Successfully reported this slideshow.
SASI: Cassandra on the Full Text Search Ride (DuyHai DOAN, DataStax) | C* Summit 2016

Upcoming SlideShare
Loading in …5
×
No Downloads
No notes for slide
- 1. SASI, Cassandra on the full text search ride DuyHai DOAN – Apache Cassandra evangelist
- 2. 1 SASI introduction 2 SASI cluster-wide 3 SASI local read/write path 4 Query planner 5 Some benchmarks 6 Take away 2© DataStax, All Rights Reserved.
- 3. SASI introduction
- 4. What is SASI ? © DataStax, All Rights Reserved. 4 • SSTable-Attached Secondary Index à new 2nd index impl that follows SSTable life-cycle • Objective: provide more performant & capable 2nd index
- 5. Who created it ? © DataStax, All Rights Reserved. 5 Open-source contribution by an engineers team
- 6. Why is it better than native 2nd index ? © DataStax, All Rights Reserved. 6 • follow SSTable life-cycle (flush, compaction, rebuild …) à more optimized • new data-strutures • range query (<, ≤, >, ≥) possible • full text search options
- 7. © DataStax, All Rights Reserved. 7 Demo
- 8. SASI cluster-wide
- 9. Distributed index © DataStax, All Rights Reserved. 9 On cluster level, SASI works exactly like native 2nd index H A E D B C G F UK user1 user102 … user493 US user54 user483 … user938 UK user87 user176 … user987 UK user17 user409 … user787
- 10. Distributed search algorithm © DataStax, All Rights Reserved. 10 H A E D B C G F coordinator 1st round Concurrency factor = 1
- 11. Distributed search algorithm © DataStax, All Rights Reserved. 11 H A E D B C G F coordinator Not enough results ?
- 12. Distributed search algorithm © DataStax, All Rights Reserved. 12 H A E D B C G F coordinator 2nd round Concurrency factor = 2
- 13. Distributed search algorithm © DataStax, All Rights Reserved. 13 H A E D B C G F coordinator Still not enough results ?
- 14. Distributed search algorithm © DataStax, All Rights Reserved. 14 H A E D B C G F coordinator 3rd round Concurrency factor = 4
- 15. Concurrency factor formula © DataStax, All Rights Reserved. 15 • more details at: http://www.planetcassandra.org/blog/cassandra-native-secondary-index- deep-dive/
- 16. Concurrency factor formula © DataStax, All Rights Reserved. 16 But right now … So initial concurrency factor always = max(1, negative number) = 1 for 1st query round with SASI ...
- 17. Caveat 1: non restrictive filters © DataStax, All Rights Reserved. 17 H A E D B C G F coordinator Hit all nodes eventually L
- 18. Caveat 1 solution : always use LIMIT © DataStax, All Rights Reserved. 18 H A E D B C G F coordinator SELECT * FROM … WHERE ... LIMIT 1000
- 19. Caveat 2: 1-to-1 index (user_email) © DataStax, All Rights Reserved. 19 H A E D B C G F coordinator Not found WHERE user_email = ‘xxx'
- 20. Caveat 2: 1-to-1 index (user_email) © DataStax, All Rights Reserved. 20 H A E D B C G F coordinator Still no result WHERE user_email = ‘xxx'
- 21. Caveat 2: 1-to-1 index (user_email) © DataStax, All Rights Reserved. 21 H A E D B C G F coordinator At best 1 user found At worst 0 user found WHERE user_email = ‘xxx'
- 22. Caveat 2 solution: materialized views © DataStax, All Rights Reserved. 22 For 1-to-1 index/relationship, use materialized views instead CREATE MATERIALIZED VIEW user_by_email AS SELECT * FROM users WHERE user_id IS NOT NULL and user_email IS NOT NULL PRIMARY KEY (user_email, user_id) But range queries ( <, >, ≤, ≥) not possible …
- 23. Caveat 3: fetch all rows for analytics use-case © DataStax, All Rights Reserved. 23 H A E D B C G F coordinator Client
- 24. Caveat 3 solution: use co-located Spark © DataStax, All Rights Reserved. 24 H A E D B C G F Local index filtering in Cassandra Aggregation in Spark Local index query
- 25. SASI local read/write path
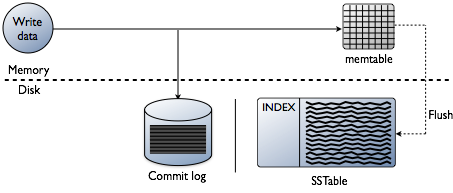
- 26. Local write path © DataStax, All Rights Reserved. 26 Index files are built • on memtable flush • on compaction flush To avoid OOM, index files are split into chunk of • 1Gb for memtable flush • max_compaction_flush_memory_in_mb for compaction flush
- 27. Local write path data structures © DataStax, All Rights Reserved. 27 Index mode, data type Data structure Usage PREFIX, text Guava ConcurrentRadixTree name LIKE 'John%' CONTAINS, text Guava ConcurrentSuffixTree name LIKE ’%John%' name LIKE ’%ny’ PREFIX, other JDK ConcurrentSkipListSet age = 20 age >= 20 AND age <= 30 SPARSE, other JDK ConcurrentSkipListSet age = 20 age >= 20 AND age <= 30 suitable for 1-to-N index with N ≤ 5
- 28. OnDiskIndex files © DataStax, All Rights Reserved. 28 SStable1 SStable2 user_id4 FR user_id1 US user_id5 FR user_id3 UK user_id2 DE OnDiskIndex1 FR US OnDiskIndex2 UK DE B+Tree-like data structures
- 29. Local read path © DataStax, All Rights Reserved. 29 • first, optimize query using Query Planer (see later) • then load chunks (4k) of index files from disk into memory • perform binary search to find the indexed value(s) • retrieve the corresponding partition keys and push them into the Partition Key Cache à Yes, currently SASI only keep partition key(s) so on wide partition it’s not very optimized ...
- 30. Binary search using OnDiskIndex files © DataStax, All Rights Reserved. 30 Data Block1 Data Block2 Data BlockN Pointer Block Pointer Block … Root Pointer Block Pointer Level 2 Pointer Level 3 Pointer Root Level Data Level Pointer Block Pointer Block Pointer Block Pointer Block… Pointer Block Pointer Block Pointer Block… Pointer Level 1 Data Block3 …
- 31. Query Planner
- 32. Query planner © DataStax, All Rights Reserved. 32 • build predicates tree • predicates push-down & re-ordering • predicate fusions for != operator
- 33. Query optimization example © DataStax, All Rights Reserved. 33 WHERE age < 100 AND fname LIKE 'p%' AND fname != 'pa%' AND age > 21
- 34. Query optimization example © DataStax, All Rights Reserved. 34 AND is associative and commutative
- 35. Query optimization example © DataStax, All Rights Reserved. 35 != transformed to exclusion on range scan
- 36. Query optimization example © DataStax, All Rights Reserved. 36 AND is associative and commutative
- 37. Some benchmarks
- 38. Hardware specs 13 bare-metal machines • 6 CPU HT (12 vcores) • 64Gb RAM • 4 SSDs in RAID0 for a total of 1.5Tb Data set • 13 billions of rows • 1 numerical index with 36 distinct values • 2 text index with 7 distinct values • 1 text index with 3 distinct values © DataStax, All Rights Reserved. 38
- 39. Benchmark results Full table scan using co-located Spark (no LIMIT) © DataStax, All Rights Reserved. 39 Predicate count Fetched rows Query time in sec 1 36 109 986 609 2 2 781 492 330 3 1 044 547 372 4 360 334 116
- 40. Benchmark results Full table scan using co-located Spark (no LIMIT) © DataStax, All Rights Reserved. 40 Predicate count Fetched rows Query time in sec 1 36 109 986 609 2 2 781 492 330 3 1 044 547 372 4 360 334 116
- 41. Benchmark results Beware of disk space usage for full text search !!! Table albums with ≈ 110 000 records, 6.8Mb data size © DataStax, All Rights Reserved. 41
- 42. Take Away
- 43. SASI vs search engines SASI vs Solr/ElasticSearch ? • Cassandra is not a search engine !!! (database = durability) • always slower because 2 passes (SASI index read + original Cassandra data) • no scoring • no ordering (ORDER BY) • no grouping (GROUP BY) à Apache Spark for analytics If you don’t need the above features, SASI is for you! © DataStax, All Rights Reserved. 43
- 44. SASI sweet spots SASI is a relevant choice if • you need multi criteria search and you don't need ordering/grouping/scoring • you mostly need 100 to 10000 of rows for your search queries • you always know the partition keys of the rows to be searched for (this one applies to native secondary index too) • you want to index static columns (SASI has no penalty since it indexes the whole partition) © DataStax, All Rights Reserved. 44
- 45. SASI blind spots SASI is a poor choice if • you have very wide partitions to index, SASI only indexes the partition offset (but it will change with CASSANDRA-11990 merged to trunk) • you have strong SLA on search latency, for example few millisecs requirement • ordering of the search results is important for you © DataStax, All Rights Reserved. 45
- 46. © DataStax, All Rights Reserved. 46 Q & A ! "
- 47. © DataStax, All Rights Reserved. 47 Thank You @doanduyhai duy_hai.doan@datastax.com https://academy.datastax.com/
Public clipboards featuring this slide
No public clipboards found for this slide