
This post is about how Yelp is transitioning from the management of Cassandra clusters in EC2 to orchestrating the same clusters in production on Kubernetes. We will start by discussing the EC2-based deployment we have used for the past few years, followed by an introduction to the Cassandra operator, its responsibilities, the core reconciliation workflow of the operator, and finally, the etcd locking we employ for cross-region coordination.
Cassandra is a distributed wide-column NoSQL datastore and is used at Yelp for both primary and derived data. Yelp’s infrastructure for Cassandra has been deployed on AWS EC2 and ASG (Autoscaling Group) for a while now. Each Cassandra cluster in production spans multiple AWS regions. A synapse-based seed provider is used during Cassandra cluster bootstrap. AWS EBS is used for storing data and EBS snapshots are used for backups. Intra-AZ mobility of EBS between EC2 instances provides better separation between stateless compute and stateful storage. This separation makes the job of an orchestrator simpler too, as we will see later.
We have been using Taskerman, our home-grown Zookeeper and AWS SQS based distributed task manager for managing deployments and lifecycles of multi-region Cassandra clusters. This has supported us well over the years and eliminated our operational toil significantly. Meanwhile, Yelp’s platform as a service - PaaSTA - has been transitioning from Mesos to Kubernetes (k8s). PaaSTA provides good abstractions for fleet management and a consistent interface for operations. With good support for state management in k8s and more importantly, being quite extensible, this provided an opportunity to explore the orchestration of Cassandra on k8s. The Kubernetes operator for Cassandra helps tie all of these together, capture database and infrastructure specific requirements, and operationalize any learnings.
The aforementioned Cassandra operator runs on Kubernetes (k8s) and Yelp PaaSTA, with one operator per production region. The operator is written in Go and uses operator-sdk. It manages Cassandra clusters through the abstractions of Custom Resources and Statefulsets. Since it runs on PaaSTA, this also allows us to pause (“Big Red Button”) the operator itself, whenever human intervention is required.
The chief responsibilities of the Cassandra operator are:
- Reconciling the runtime state of the cluster with cluster specification.
- Scaling the cluster up and down safely one Pod at a time.
- Lifecycle management: handling dying nodes and pods and replacing them with healthy replacements.
- Coordinating with operators managing the same cluster in other regions.
- Safely allowing for new changes to be deployed and the cluster to be restarted.
- Garbage collection of crashing and pending pods upon reconciliation.
- Balancing resource utilization and availability with affinities.
- Managing the TLS credentials required Cassandra internode and client-server authentication.
Before we delve deeper into operator workflow, let’s have a brief look at what goes into a typical Cassandra pod.
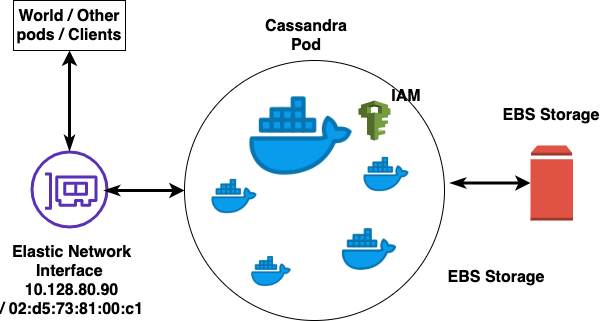
Every Cassandra pod contains one Cassandra container and a few sidecars. The sidecar containers are:
- HAcheck container for health checking and reporting availability to our service discovery mechanism.
- Cron container where we run periodic tasks such as those for snapshotting.
- Sensu container where we deploy our Sensu checks.
- Prometheus exporter for publishing metrics to Grafana dashboards.
- Change Data Capture (CDC) publisher to publish table changes to the Yelp Data Pipeline.
For the readiness check, we ensure every pod in a cluster in each region has Cassandra in the UN state. For liveness checking, we ensure that Cassandra is up (U) and in one of the leaving (UL) / joining (UJ) / normal (UN) states.
Operator Workflow
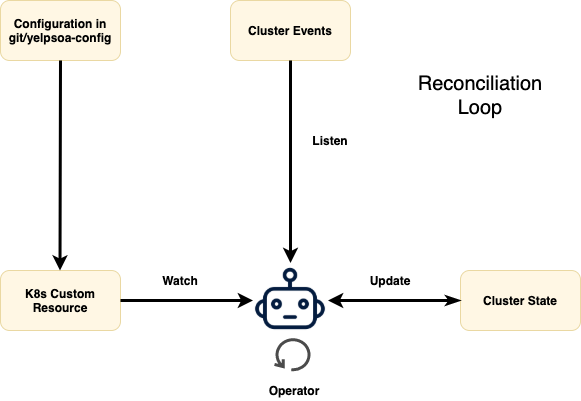
On a very high level, this is what the operator workflow looks like. The Operator watches the k8s Custom Resource (CR) (which is continually refreshed by PaaSTA based on on-disk config updates) and also listens to per-cluster events in a loop. In case the runtime state of the cluster differs from what is desired in the configuration, it updates the state to “reconcile” it with what is desired. Since these changes happen without any human intervention, safety is the number one priority. Let’s take a look at what the cluster specification looks like before jumping into the intricacies of the reconciliation loop.
Cluster Specification
# yelpsoa-configs/cassandracluster-pnw-dev.yaml
feeder_instance:
clusterName: feeder
replicas: 3
deploy_group: dev.everything
cpus: 4
mem: 8Gi
disk: 400Gi
env:
JVM_EXTRA_OPTS: "-Dcassandra.allow_unsafe_aggressive_sstable_expiration=true"
cassandraConfig:
file_cache_size_in_mb: 1024
row_cache_size_in_mb: 512
cdcEnabled: true
cdcPublisherConfig:
enable_flush: true
enable_filler_writes: true
publish_every_m: 5
This is a specification of the cluster in yelpsoa-configs, PaaSTA’s config store. Here we are creating a new “feeder” cluster of 3 replicas with 4 AWS vCPUs, 8 GiB memory, and 400 GiB EBS volume attached to each. We are also passing some Cassandra configuration overrides and additional environment variables to the cluster processes. Finally, we can see that we have enabled the CDC for this cluster with its associated configuration. Note that, in general, all of these options are not required since we have followed a “batteries included” approach wherein a new cluster with a good config and TLS can be created out-of-the-box.
This specification is wrapped into a k8s Custom Resource by PaaSTA when consumed by the operator.
Reconciliation Loop
Now that we know what the spec looks like, let’s delve deeper into the cluster update reconciliation flow.
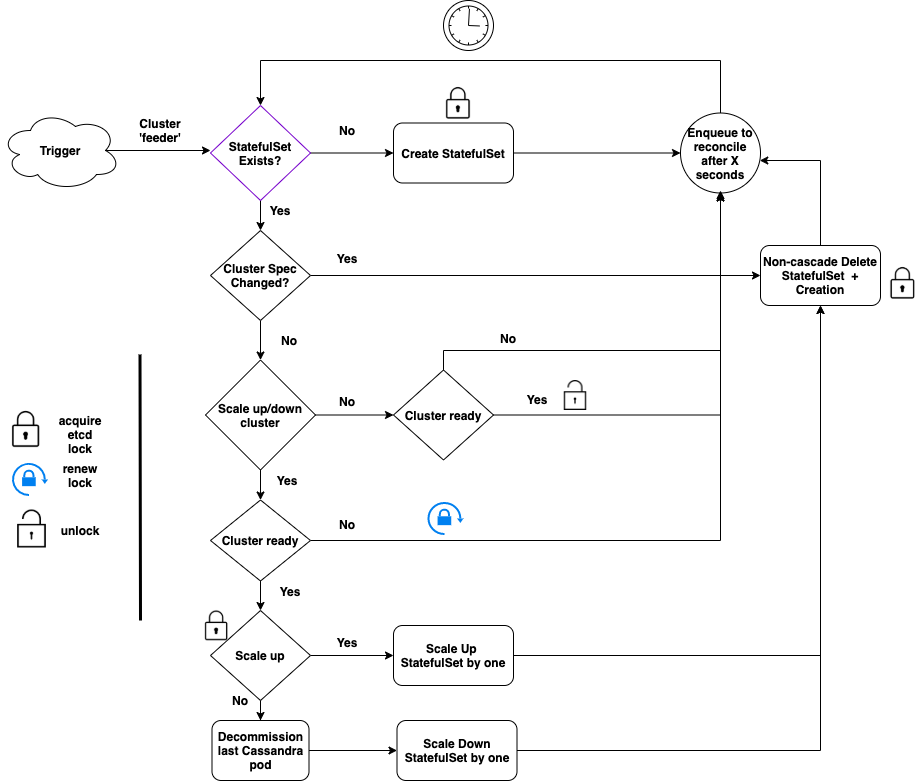
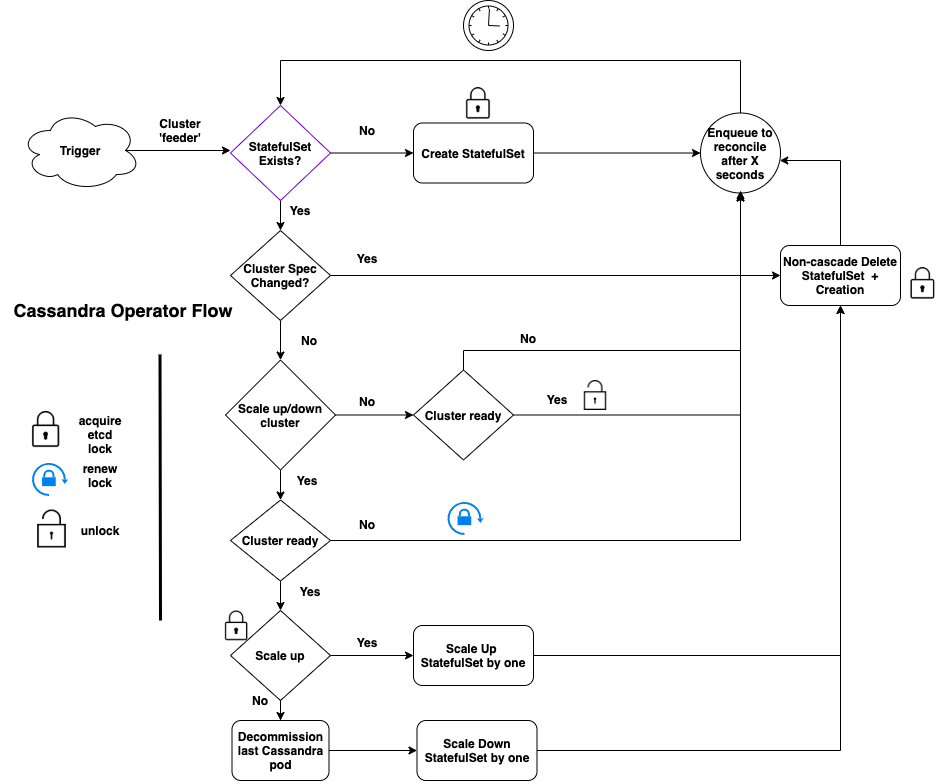
For the ‘feeder’ cluster whenever there is a new trigger, the operator does the following:
- Creation: Check if the statefulset (STS) corresponding to the cluster exists. If not, then this is pretty much straightforward in that we create a new STS and wait.
- Hash-based reconciliation: If the STS exists but the specification has been updated (say, CPU increased from 2 to 4), we need to update the STS.
- To detect if the specification has been updated, we hash the STS object excluding the number of replicas (since we handle scale up/down differently below).
- If the hash has changed, we need to update the STS.
- We explored and tested multiple in-place STS update strategies but they turned out to be flaky, breaking the operator sporadically. Instead, the operator deletes the STS without deleting its pods (“non-cascade deletion”) followed by recreation of the STS from the new spec. The new STS gets attached to the existing pods.
- This has been stable for us and, in general, much more clean and maintainable.
- After the recreation of STS, we also garbage collect pre-existing Pending and Failed pods so that STS recreates them. This has helped us in getting the STS unstuck from bad config pushes.
- Horizontal Scaling: If only the number of replicas has changed, we handle this separately because as a database there are a few actions required to manage Cassandra cluster membership before we scale up/down.
- First and foremost, since the scale up/down of a cluster is not critical, we check if the cluster is healthy before we proceed. If the cluster is unhealthy, we wait.
- If the cluster is fine for scale up, we increase STS size by one and replace it with the strategy mentioned above (delete + create).
- If the cluster is scaling down, we need to decommission the Cassandra replica first before scaling down.
- Hence, we first decommission the pod with the highest ordinal number (due to the nature of STS, this is the latest pod to join the cluster).
- Next, we decrement the STS by one and continue with STS replacement as before.
- A key thing to note is that we scale up/down by one unit at a time. This is from a safety perspective.
- End of the loop: Finally, if there is nothing to do, the operator requeues a reconcile event to check the cluster after a pre-configured ‘X’ seconds, thus completing that iteration of the controller loop.
- To avoid head-of-line blocking between clusters, we usually set the maximum number of concurrent reconciliations (“MaxConcurrentReconciles” in controller-runtime) to a high value.
- Locking: Keen observers of the flow diagram above would have noticed some locking and unlocking in it. This is the etcd locking which we use for coordination between multiple regions, and for custom resource status updates. More on this later. The key takeaway, for now, is that the operator removes etcd lock only when the cluster is ready.
Cassandra Storage
All of this orchestration has been made simpler owing to the intra-AZ mobility of AWS EBS. EBS for each pod of the cluster is provisioned dynamically from the spec with a Persistent Volume Claim (PVC) which accordingly creates the Persistent Volume (EBS in our case). A storage class defines the nature and semantics of this EBS creation. We create a storage class per cluster and it looks like something like:
# feeder is the name of the cluster
allowVolumeExpansion: true
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cassandra-ebs-feeder
parameters:
fsType: xfs
type: gp2
provisioner: kubernetes.io/aws-ebs
reclaimPolicy: Delete
volumeBindingMode: Immediate
In short, this ensures that every new pod gets a gp2 EBS volume with XFS filesystem and dynamic volume expansion. The latter allows us to resize EBS volumes on the fly with zero disruption (a topic for another exciting blog post). Finally, with volumeBindingMode of “Immediate”, we get the “compute-follows-data” model which is what we want given that data streaming can be very expensive. With this mode, the storage class ensures volumes are round-robined across multiple Availability Zones first before any of the corresponding pods are created for those volumes. This also ensures that pods are not created in a different AZ from the volume itself.
This mobility of data within the AZ also allows us to run non-production and internal workloads on AWS Spot ASGs while keeping production ones on on-demand / reserved instances, and contribute to cost savings. We use Clusterman to manage the spot and on-demand/reserved instance fleets.
Cross-region Coordination
In PaaSTA, we have deployed one k8s cluster per AWS region rather than a federated deployment. This means that there is one operator per region for Cassandra. Hence, for Cassandra clusters that span multiple regions, we need to ensure that these operators coordinate with each other. This is where etcd locking comes into play. Since we did not find any construct in operator-sdk or container-runtime for coordination between operators, we added our own locking mechanism in the operator. Since etcd is native to Kubernetes and is used for other builtin coordination, we employed it for this use case as well.
Broadly speaking, we are employing locking in the following use cases:
- During cluster creation to ensure clusters don’t bootstrap independently at the same time in different regions.
- During scale up/down of the cluster, to ensure we do it one region at a time.
- Ensuring that any breaking change to one region does not propagate to another region.
To avoid deadlocks and staleness, we couple the lock with a lease with a preset expiry. This lease is renewed by the operator as part of its reconciliation activity. The lock is released when the cluster is ready for that region.
There is so much more to write and describe here - zero-downtime migration strategies we employed, use of anti-affinity for availability, CI/CD pipeline for Cassandra deployments, use of Clusterman for fleet management, Secret management and TLS, IAMs - and much much more. However, those are reserved for sequels to this blog post. As of this post, we have migrated most of our production clusters to k8s, and migration of the remaining clusters is in progress. As always, there are more interesting challenges and opportunities in this space. If you are interested to know more about these, what better way is there than to come and work for us. We are hiring!
Acknowledgments
- Raghavendra Prabhu (author), Sheng Ran, and Matthew Mead-Briggs for the work on the Cassandra Operator. The author would also like to thank Database Reliability Engineering (DRE) and Compute Infrastructure teams for various contributions to the project.
- Logo/Icon credits: AWS Architecture Icons.
Become a Software Engineer in the DRE team at Yelp!
Interested to know more about Cassandra and Kubernetes? Join our DRE team!
View Job












