
In this article, I will talk about the CAP theorem and where these most used databases stand in the CAP theorem and a bit about these systems.
CAP stands for Consistency, Availability and Partition Tolerance.
Consistency means, if you write data to the distributed system, you should be able to read the same data at any point in time from any nodes of the system or simply return an error if data is in an inconsistent state. Never return inconsistent data.
Note: Consistency in CAP theorem is not same as Consistency in RDBMS ACID.
CAP consistency talks about data consistency across cluster of nodes and not on a single server/node.
Availability means the system should always perform reads/writes on any non-failing node of the cluster successfully without any error. This is availability is mainly associated with network partition. i.e. in the presence of network partition whether a node returns success response or an error for read/write operation.
Note: Availability in CAP theorem is not the same as the downtime we talk about in our day to day system. Example 99.9% availability of a microservice is not the same as CAP theorem Availability. CAP-Availibilty talks about if the cluster has network partition how the system will behave, whether it will start giving error or keep serving requests successfully.
Partition Tolerance means, if there is a partition between nodes or the parts of the cluster in a distributed system are not able to talk to each other, the system should still be functioning.
What is the CAP Theorem?
A distributed system always needs to be partition tolerant, we shouldn’t be making a system where a network partition brings down the whole system.
So, a distributed system is always built Partition Tolerant.
So, In simple words, CAP theorem means if there is network partition and if you want your system to keep functioning you can provide either Availability or Consistency and not both.
How a Distributed System breaks Consistency or Availability?
Scenario 1: Failing to propagate update request to other nodes.
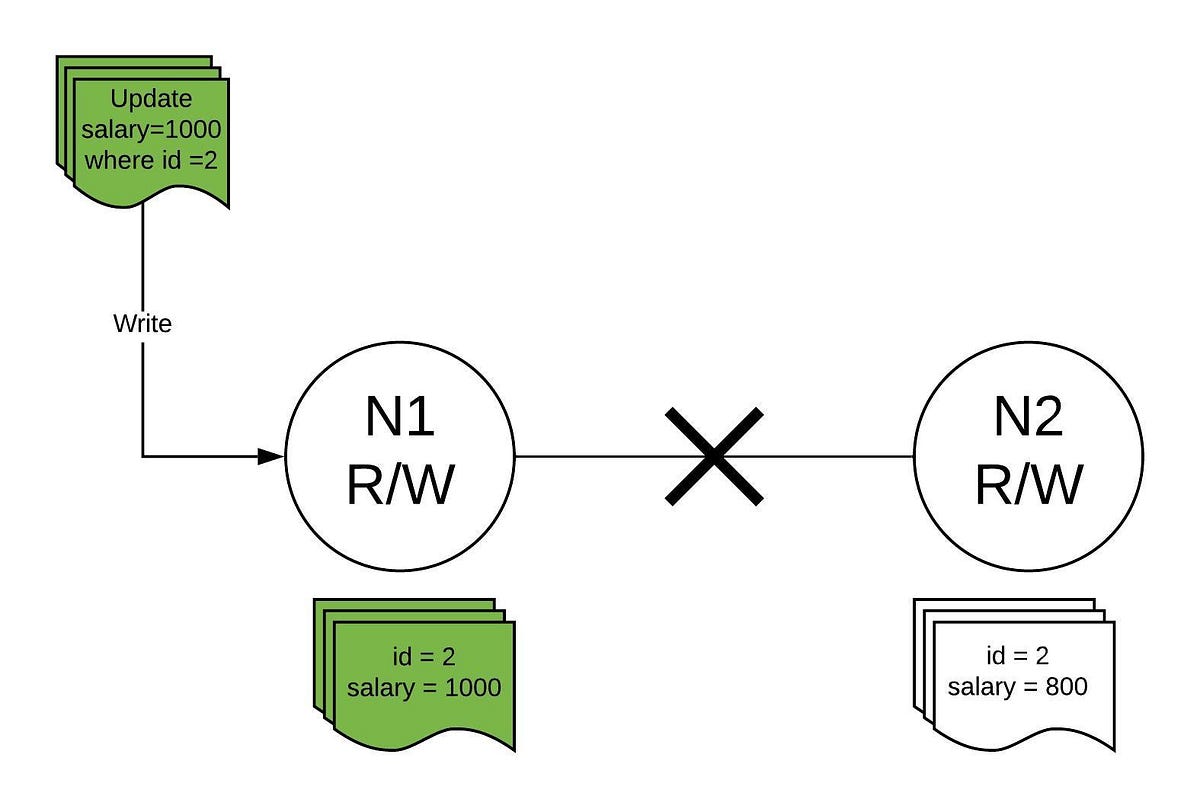
Say, we have two nodes(N1 & N2) in a cluster and both nodes can accept read and write requests.
In the above diagram, the N1 node gets an update request for id 2 and updates the salary from 800 to 1000. But, since there is network partition, hence, N1 can not send the latest update to N2.
So, when a read request comes to N2, it can do either of two things:
- Respond with whatever data it has, in this case, salary = 800, and update the data when the network partition resolves — making the system Available but Inconsistent.
- Simply return with an error, saying “I do not have updated data” — making a system Consistent but Unavailable by not returning inconsistent data.
Scenario 2: Single Leader based system where read and write come to the leader and all other nodes stays updated from the leader and remain on standby in case the leader goes down.
The problem with this system is that, if the leader disconnects from the cluster or the clients are not able to connect to the leader due to network partition between the client and leader, the system can not accept write requests until the new leader is elected. Making these kinds of system Consistent and not Available.
A single leader based system that accepts reads and writes, should never be categorized under Availability.
Disclaimer: CAP theorem is too simplistic to describe today’s distributed systems. Distributed systems today provided a bit of each C, A, and P based on the configurations of the system. Hence, it would not be correct to categorize these systems in either CP or AP.
Being said that, their default behavior could be CP or AP. Which we will discuss shortly.
Many of us have seen the below diagram. Databases in CAP theorem. This categorization of the databases is not entirely correct.
It’s no brainer that all RDBMS are Consistent as all reads and writes go to a single node/server.
How about availability? You might say, it is one single server and hence a single point of failure. So, how it’s categorized under Availability?
As I said earlier CAP-Availability is not the same as day to day availability/downtime we talk about. In a single node system, there will not be any network partition hence if the node is up, it will always return success for any read/write operation and hence available.
What happens when you replicate these Relational Databases?
We can make such systems using any cluster manager systems like Zookeeper or etcd.
So does this mean these replicated relational databases are Available?
Not entirely, let’s see how.
- If a leader disconnects from the cluster, it takes a few seconds to elect a new leader. So, definitely not an available system.
- A client can always disconnect from the leader due to network partition even if both client and leader node is running fine. Hence making it unavailable.
Note: The Second point mentioned above can be solved if the client applications also keep heartbeat of the leader and initiate leader election in case it’s not able to connect to the leader. Still definitely not easy to achieve in RDBMS :) It would just complicated to put such logic in client applications.
What about consistency when data is replicated?
- If the data is read and written from only master/primary node it's always Consistent.
- If the read requests are sent to any of the secondary, we will lose consistency and might serve inconsistent data in case of network partition or say master takes time to replicate data.
In summary, a relational database can have downtime or be unavailable but it is always CAP-Available.
If RDBMS server is replicated, it's consistent — only if reads and writes are performed only through the leader or master node.
We generally categorize RDBMS in CA. Because Relational databases are a single node system and hence we do not need to worry about partition tolerance and hence if RDBMS server is up and running, it will always respond success for any read/write operation.
Things you should know about MongoDB:
- MongoDB is a single leader based system that can have multiple replicas. These replicas update themselves asynchronously from Leader’s OpLog.
- Each node maintains the heartbeat of every other node to keep track if other replicas or leader is alive or dead.
- If the leader/primary node goes down, replicas can identify and elect a new leader based on priority, if they can form the majority. More on this here.
Consistency and Availability in MongoDB
Scenario 1: Default Behavior — Both read and write from primary/leader
By default, Mongo DB Client(MongoDB driver), sends all read/write requests to the leader/primary node.
Again this default behavior allows Mongo DB to be a consistent system but not available due to the below reasons:
- If a leader disconnects from the cluster, it takes a few seconds to elect a new leader. So, making it unavailable for writes and reads.
- A client can always disconnect from the leader due to network partition even if both client and leader node is running fine. Hence making it unavailable.
So, if we use MongoDB client with its default behavior, MongoDB behaves as a Consistent system and not Available.
Scenario 2: Enable read from secondary
As we have seen in the previous scenario when a new leader is getting elected or if the client disconnects from the leader. Our system is not available for both read and write.
How do we change that and make the system available for reads?
We could simply configure read-preference mode in MongoDB client to read from any secondary nodes.
But, by doing so we are breaking consistency. Now, a write to primary/leader can be successful but, secondary’s might not have updated the latest data from primary due to any reason.
So, with this setup, you get high availability for reads but lose consistency and inturn you get eventual consistency.
How can we solve the above problem in MongoDB and make the system “highly consistent” even when reads are going to multiple secondary nodes?
MongoDB solves this by using “write concerns”.
While writing data to MongoDB you could pass a write option. Mentioning the number of nodes the data should be written to make a write successful or you can pass “majority”, which indicates write would be successful if primary got acknowledgment from the majority of nodes.
This way you can even have the same data in all nodes if you write to all nodes.
Note: MongoDB has heartbeat timeout configured to default 10 seconds, so if a leader dies other nodes would figure out at 10th second and start leader election.
As per the document, the median time before a cluster elects a new primary should not typically exceed 12 seconds as per default settings. More on leader election here.
In Summary, MongoDB can always be Consistent based on how you configure your client and the way you write data(using write options) and can be always available for reads but you can never make write always available, there will always be downtime when:
a) the new leader is getting elected
b) the client driver disconnects from the leader
In Cassandra, any coordinator nodes can accept read or write requests and forwards requests to respective replicas based on the partition key. Hence even if a replica/node goes down, others can serve the read/write requests. So, is it safe to say Cassandra is always available?
Hmmm not entirely, we will find out soon why.
In Cassandra, we can define the replication factor. If set to 3, Cassandra will replicate data to three nodes.
Scenario 1: Default case — No Consistency level defined
In this case, when a write is sent to any node, the node returns success once the data is written to that node.
The other two replica nodes(if the replication factor is set to 3) will eventually get the data and hence sometimes Cassandra DB is called as it eventually consistent DB.
If for some reason the third replica didn’t get the updated copy of the data, it could be due to latency or network partition, or you just lost the packet.
Then, If you happen to read data from the node which is not updated yet, you will get inconsistent data.
Hence in its default settings, Cassandra is categorized as AP(Available and Partition Tolerant)
Scenario 2: Read/Write request with Consistency levels
In Cassandra, we can define the read/write consistency level in the Cassandra client while creating the Cassandra Session.
How Does Consistency level impacts write?
It ensures a write is successful only if it has written to the number of nodes given in the Consistency Level. These values can be ANY or ONE or QUORUM or ALL or a Number.
How Does the Consistency level impact read?
If the consistency level is THREE, Cassandra will read from the three replicas and return the latest data among the 3 nodes and update the other outdated replicas too.
So, Just by setting consistency level to QUORUM(majority) consistency. As these consistency level settings are applied to both reads and writes. We can achieve 100% consistency.
So, what happens to Availability?
Larger the consistency level, the availability of the system will decrease.
Example: Say we have set Consistency level to THREE, for a Cassandra DB whose replication factor is 3.
If one of the replicas disconnects from the cluster, both read and write will start to fail, making the system Unavailable for both read and write.
In Summary, Cassandra is always available but once we start tweaking it to make more consistent, we lose availability.
The below table summarizes where each DB with a different set of configurations sits on the CAP theorem.
The table is set up for:
- MongoDB with 5 nodes
- Cassandra with a replication factor of 5
- single-node RDBMS server
In this blog post, we saw how each DB is categorized in the CAP theorem and how it's difficult to categorize them, as they all behave in a different way based on how you configure them.
Hope this helps :)








