

Upgrade your Feast Online feature store with Cassandra
It’s quite common today for high-growth apps and services to employ machine learning (ML) to deliver their core services. Many artificial intelligence and machine learning (AI/ML) teams are challenged to find an efficient way to scale ML practices to production in a robust way; as a set of best practices emerged (now collectively termed “MLOps”), the concept of a feature store has appeared as a central piece of software essential to modern data architecture.
Of the several feature stores available today, Feast is gaining popularity due to its flexibility, its ease of use, and the fact that, unlike most other equivalent solutions, it’s open source (under the Apache 2.0 license).
The new feast-cassandra plugin enables developers to configure DataStax Astra DB, as well as any Apache Cassandra® cluster, as the online data store for Feast, an open source feature store for ML. The plugin is available to install via pip from the Python Package Index.
Feast’s modularity enables third-party database technologies to integrate with its core engine. Switching Feast to use Astra DB or Cassandra as an online store is simply a matter of editing a couple of lines in the store’s configuration file.
What’s a feature store?
The typical task in ML consists of building a model and training it with some initial labeled data (the learning phase). This enables the model to provide predictions when presented with new input.
Think of a model to detect fake reviews on your e-commerce website. First you “show” it many reviews along with their legitimate and fake actual status. Once you have “trained” it well enough, you can employ it to improve the quality of your service by automatically weeding out unwanted contributions.
A crucial concept is that of a feature: a specific value that describes an input to the model. This could be, for instance, the count of all-caps words in the review text, the presence or absence of a particular adjective, or the time the review was submitted. Choosing which features to use when designing a model is very important to its success, and a good deal of a data scientist’s time is spent on “feature engineering.”
Feature stores are not themselves databases, but tools that manage data stored in other database systems. A feature store aims to solve some of the most vexing problems data engineers struggle with, namely:
- Different teams having to “reinvent the wheel” (the features and the data pipelines) and not sharing their efforts easily within an organization
- Lack of systematic control over the data used in training versus in running a model (“training-serving skew”)
- The search for a unified engine to track “backfill” computations and similar ordinary data administration tasks
- The need for incremental updates to the data set while retaining the possibility of retrieving point-in-time data snapshots
- An abstract layer for data access that “speaks” the language used by the rest of the ML stack, regardless of the actual backing infrastructure
These needs are addressed by the introduction of a feature store as the central hub for a production data pipeline. At its heart, a feature store handles the relationship between the “offline” store (which retains all data history) and the “online” store (where only the latest value of features is kept). The latter is typically used in providing predictions and must be accessed fast and reliably.
What is Feast?
Feast is an open-source feature store solution that can be configured to use several data sources (from databases to streams) and several online data stores.
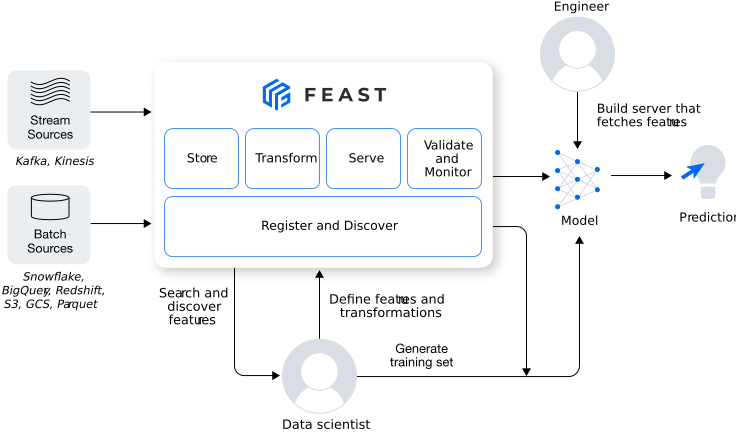
Feast-at-a-glance (Source: Feast.dev)
Feast has a Python API that makes it easy to get started quickly, without having to learn any domain-specific language. Integration with existing ML tools is usually a matter of loading the features differently, and little more. Even most of the “configuration,” such as defining the features of a project, is done in the Python programming language.
Other tasks, such as syncing the offline store into the online store for the latest data, can be scheduled on a periodic basis (and simply consists of system commands to be executed).
Feast enables quick and standardized access for the latest features for a dataset, as well as historical retrievals (like point-in-time queries, such as “what were the feature values as of last month?”), which are crucial for reproducibility, versioning, and accountability.
This is just the core idea. Feast ships with other components and layers making it a valuable pillar of a modern AI/ML data stack. For a deeper understanding of how Feast is structured, please refer to the concepts page on Feast’s documentation.
Online and Offline Feature Stores
Offline storage layers store months or even years of historical feature data in bulk, for the purpose of training ML algorithms. This data is typically stored by extending existing data warehouses, data lakes and/or cloud object storage to avoid data silos.
Feast’s blog describes “Online storage layers are used to persist feature values for low-latency lookup during inference. Responses are served through a high-performance API backed by a low-latency database. They typically only store the latest feature values for each entity, essentially modeling the current state of the world. Online stores are usually eventually consistent, and do not have strict consistency requirements for most ML use cases.They are usually implemented with key-value stores.” For more on this topic, please read this excellent explanation by Feast.
The Cassandra/Astra DB plugin for Feast
The feast-cassandra plugin enables the usage of Astra DB, or any Cassandra cluster, as an online feature store for Feast. When using Astra DB in particular, Feast users can run a model in production that relies on Astra DB’s resilient architecture for providing the data on which predictions are evaluated. This has several advantages:
- Astra DB is a database built on the robust Cassandra engine with its blazing fast write (and read) operations, 100% uptime and linear scalability.
- Astra DB also inherits Cassandra’s eventually consistent database design with configurable consistency levels.
- Astra DB supports multi-region with active-active configurations, making it possible for a single database to guarantee very low latencies from anywhere in the world.
- Astra DB is serverless. There is no fixed cost in using it; billing is based solely on storage, network, and read/write operations. It autoscales to zero when unused, making costs extremely low on any cloud.
- Astra DB is an intelligently auto-scaling cloud service, so there is zero operational burden. This frees busy data engineers to focus on things other than database operations or capacity planning.
As with any Cassandra-based system, you have the assurance that the size of the feature set will not be an issue, as the core design is to handle big data.
The feast-cassandra plugin, at its core, is an implementation of the OnlineStore “abstract interface” (a “class,” in Python language), which must offer four methods in order to be “driven” by the core Feast runtime:
update, called to alter the nature of the stored entities (e.g. when adding a new feature)teardown, called when the whole storage is to be removedonline_write_batch, called when saving features in the online store (for instance, as the result of a “materialize” operation that syncs the latest value of the features from the offline storage)online_read, used to retrieve the features associated with a given set of entities
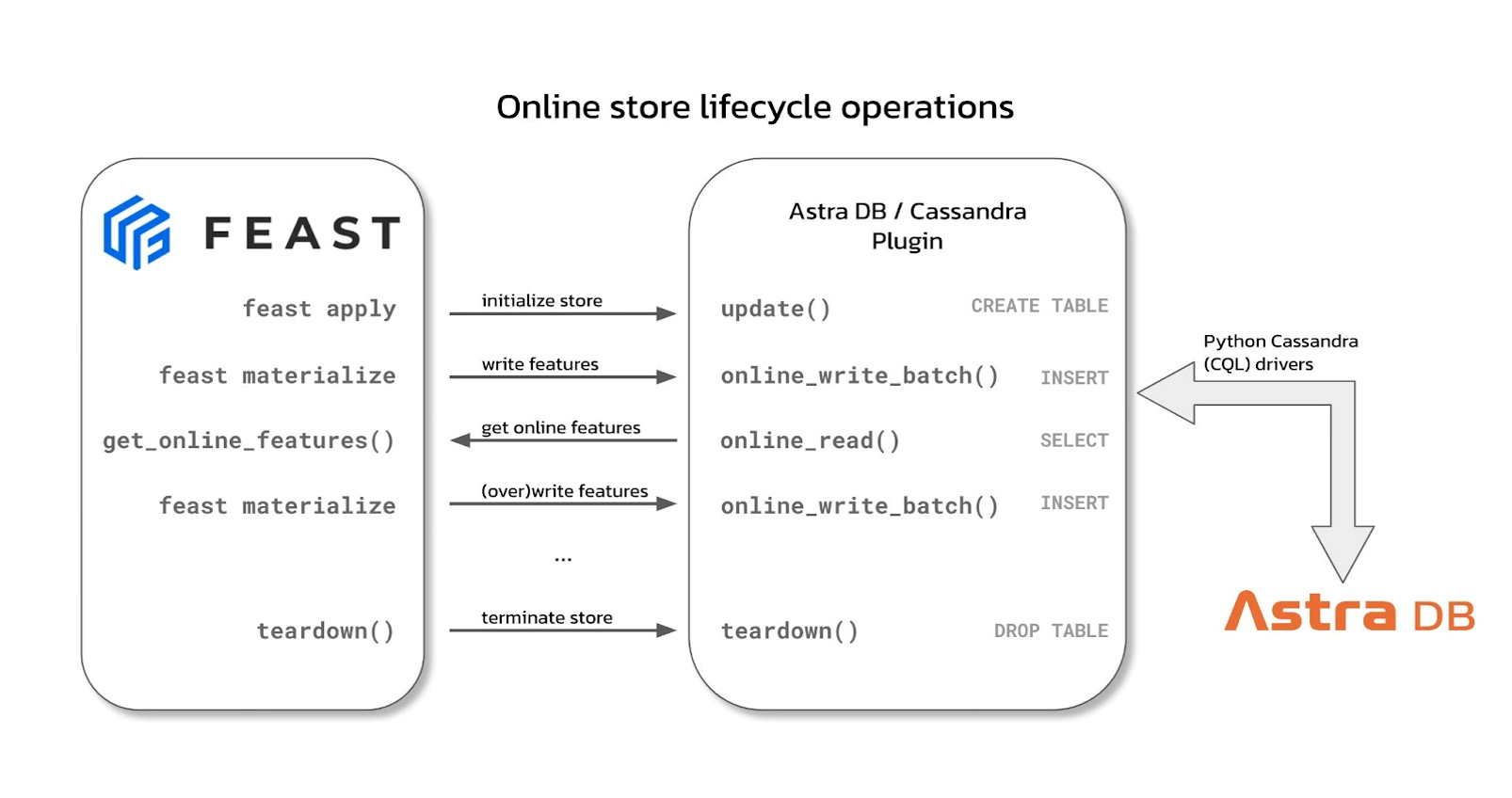 Online store lifecycle operations.
Online store lifecycle operations.
The plugin can be installed through the Python package index here, while its source code can be found here. Improvement proposals, as well as bug reports, are welcome as Github issues and will be addressed by our team.
Create your first Astra DB-backed feature store
Here’s how to get started with Feast and Astra DB as its online store backend:
- Install Feast with
pip install feast(requires Python 3.7+. Use of a virtual environment is strongly suggested). - Install the plugin with
pip install feast-cassandra. - Create an Astra DB instance that will be managed by the plugin as far as table creation and data I/O are concerned.
- Create a Database Token with “DB Administrator” role (this will provide DB authentication to the plugin).
- Download the “Secure connect bundle” for accessing the database.
- Initialize a Feast feature store (the quickstart on Feast’s documentation shows how this is accomplished).
- Edit the
feature_store.yamlfile to set Astra DB: theonline_storesection of the file should look like:
[...]
online_store:
type: feast_cassandra_online_store.cassandra_online_store.CassandraOnlineStore
secure_bundle_path: /path/to/secure/bundle.zip
keyspace: KeyspaceName
username: Client_ID
password: Client_Secret
In the above, replace the location of the secure bundle file downloaded earlier, make sure the KeyspaceName matches what was chosen when creating the database, and provide the Client_ID and Client_Secret found in the DB token. At this point, the rest of the Feast quickstart can be executed to see Feast in action with Astra DB.
Well, you’re off and running. With Astra DB, your noSQL skills aren’t stuck on a specific cloud provider so you only have to learn it once. Also, Cassandra-based systems offer the best of Amazon's Dynamo distributed storage and replication techniques combined with Google's Bigtable data and storage engine model. Experience Feast with autoscaling that doesn’t require multiple other commercial cloud services to autoscale!
Note: if you’re not using Astra DB yet, it’s easy to get started. Register for a free account (no credit card is required). You can use your Google, GitHub, or email account to sign in with a few clicks. The free plan gives you a monthly allowance, which is enough to cover even small production workloads.





