
In first post of this series we discussed about what is cassandra, what are the benefits of using cassandra. We also discussed a little bit about from where cassandra came and finally we looked at the architecture of cassandra and discussed some important terms like snitch, gossip, data replication, partitioner etc.
In this post we will see how cassandra Read/Write mechanism works.
Let’s discuss about some key components of cassandra first before discussing about Read/Write. Important components of cassandra can be summarized as below:
1: Node – This is the most basic component of cassandra and it is the place where data is stored.
2: Data Center – In simplest term a datacenter is nothing but a collection of nodes. A datacenter can be a physical datacenter or virtual datacenter.
3: Cluster – Collection of many data centers is termed as cluster.
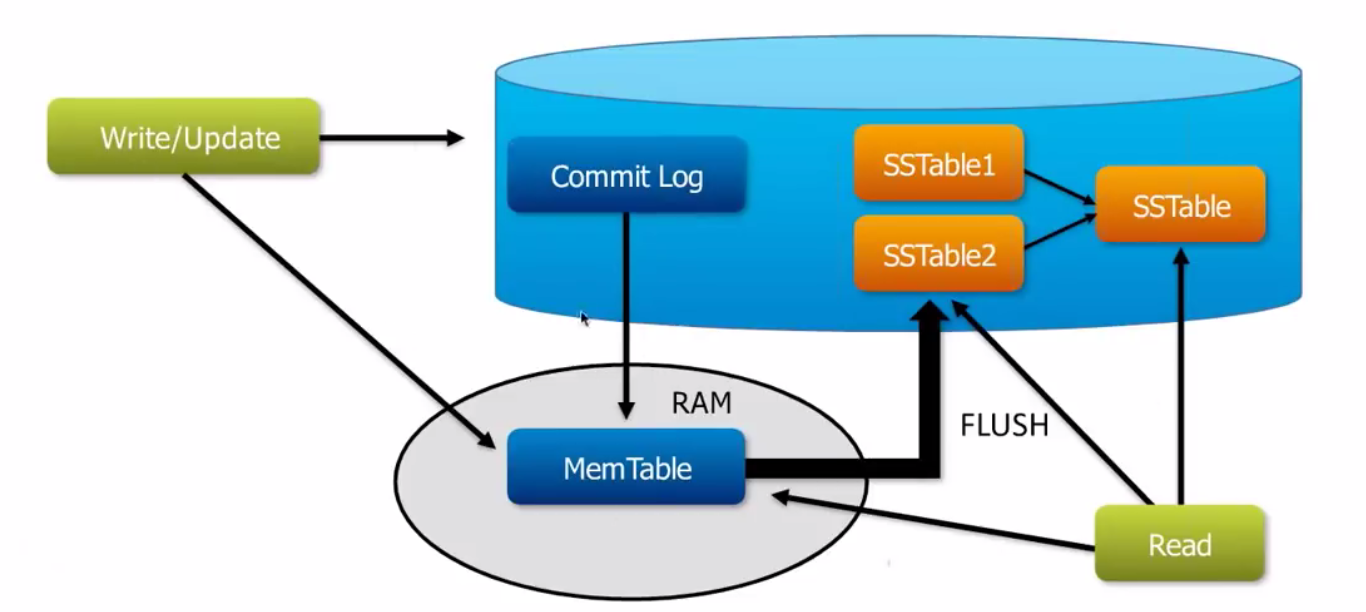
4: Commit Log – Every write operation is written to Commit Log. Commit log is used for crash recovery. After all its data has been flushed to SSTables, it can be archived, deleted, or recycled.
5: Mem-table – A mem-table is a memory-resident data structure. Data is written in commit log and mem-table simultaneously. Data stored in mem-tables are temporary and it is flushed to SSTables when mem-tables reaches configured threshold.
6: SSTable – This is the disk file where data is flushed when Mem-table reaches a certain threshold.
7: Bloom filter − These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
8: Cassandra Keyspace – Keyspace is similar to a schema in the RDBMS world. A keyspace is a container for all your application data.
9: CQL Table – A collection of ordered columns fetched by table row. A table consists of columns and has a primary key.
Cassandra Write Operation
Since cassandra is a distributed database technology where data are spread across nodes of the cluster and there is no master-slave relationship between the nodes, it is important to understand how data is stored (written) within the database.
Cassandra processes data at several stages on the write path, starting with the immediate logging of a write and ending in with a write of data to disk:
- Logging data in the commit log
- Writing data to the memtable
- Flushing data from the memtable
- Storing data on disk in SSTables
When a new piece of data is written, it is written at 2 places i.e Mem-tables and in the commit.log on disk ( for data durability). The commit log receives every write made to a Cassandra node, and these durable writes survive permanently even if power fails on a node.
Mem-tables are nothing but a write-back cache of data partition. Writes in Mem-tables are stored in a sorted manner and when Mem-table reaches the threshold, data is flushed to SSTables.
Flushing data from the Mem-Table
Data from Mem-table is flushed to SSTables in the same order as they were stored in Mem-Table. Data is flushed in following 2 conditions:
- When the memtable content exceeds the configurable threshold
- The commit.log space exceeds the commitlog_total_space_in_mb
If any of the condition reaches, cassandra places the memtables in a queue that is flushed to disk. The size of queue can be configured by using options memtable_heap_space_in_mb or memtable_offheap_space_in_mb in cassandra.yaml configuration file. Mem-Table can be manually flushed using command nodetool flush
Data in the commit log is purged after its corresponding data in the memtable is flushed to an SSTable on disk.
Storing data on disk in SSTables
Memtables and SSTables are maintained per table. The commit log is shared among tables. Memtable is flushed to an immutable structure called and SSTable (Sorted String Table).
Every SSTable creates three files on disk
- Data (Data.db) – The SSTable data
- Primary Index (Index.db) – Index of the row keys with pointers to their positions in the data file
- Bloom filter (Filter.db) – A structure stored in memory that checks if row data exists in the memtable before accessing SSTables on disk
Over a period of time a number of SSTables are created. This results in the need to read multiple SSTables to satisfy a read request. Compaction is the process of combining SSTables so that related data can be found in a single SSTable. This helps with making reads much faster.
The commit log is used for playback purposes in case data from the memtable is lost due to node failure. For example the node has a power outage or someone accidently shut it down before the memtable could get flushed.


Read Operation
Cassandra processes data at several stages on the read path to discover where the data is stored, starting with the data in the memtable and finishing with SSTables:
- Check the memtable
- Check row cache, if enabled
- Checks Bloom filter
- Checks partition key cache, if enabled
- Goes directly to the compression offset map if a partition key is found in the partition key cache, or checks the partition summary if not.
-
If the partition summary is checked, then the partition index is accessed
- Locates the data on disk using the compression offset map
- Fetches the data from the SSTable on disk


There are three types of read requests that a coordinator sends to replicas.
- Direct request
- Digest request
- Read repair request
The coordinator sends direct request to one of the replicas. After that, the coordinator sends the digest request to the number of replicas specified by the consistency level and checks whether the returned data is an updated data.
After that, the coordinator sends digest request to all the remaining replicas. If any node gives out of date value, a background read repair request will update that data. This process is called read repair mechanism.
I hope this post is informational to you. Feel free to share this on social media if it is worth sharing. Be sociable 






