
Cassandra was very new to me when I joined the vCloud Air operations team back in 2015. Over last 1.5 years I have got a bit of understanding about cassandra now and it provoked me to learn this wonderful database technology.
To start my journey with Cassandra, I am following training course from Infinite-Skills and youtube videos along with documentation available from datastax.
As my journey will progress, I will keep writing and sharing my experience of learning about cassandra.
This is very first post of learning cassandra series where I will try to touch down few basic things about cassandra.
What is cassandra?
cassandra is a NoSQL database technology. NoSQL is referred as not only SQL and it means an alternative to traditional relational database technologies like MySQL, Oracle, MSSQL. Apache cassandra is a distributed database. With cassandra database do not lives only on one server but is spread across multiple servers. This allows database to grow almost infinitely as it is no longer dependent on specifications of one server.
It is a big data technology which provides massive scalability.
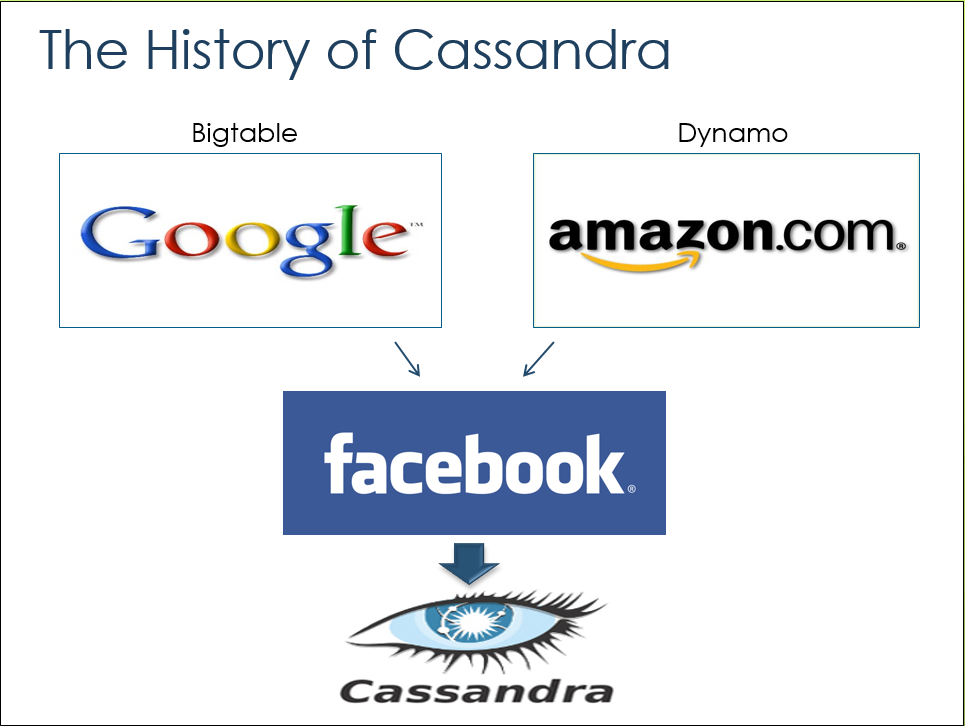
History of Cassandra
Cassandra project was developed by Avinash Lakshman (the author of Amazon Dynamo) and Prashant Malik at Facebook, to solve their Inbox-search problem. In combination with Google BigTable and Amazon DynamoDB, they developed Cassandra.
Cassandra code was published in July 2008 as free software, under the Apache V2 license. Since then Cassandra is developed and maintained by the Apache foundation for the community version and by DataStax for the enterprise and commercial versions.


Why use cassandra?
The top features which makes cassandra so powerful can be summarized as below:
1: Fault Tolerant/High Availability
Cassandra is deployed as a clustered system which contains many node. All the nodes replicate data to each other for fault-tolerance. Even if few nodes from a cassandra cluster goes down, data is not lost. Data Replication across multiple data centers is supported. Also the failed nodes can be replaced with no downtime.
2: Decentralized
In a cassandra cluster, each node has same functionality. There is no master-slave concept with cassandra and thus there are no single points of failure. Every node in the cluster is identical. Cassandra cluster is not impacted by network bottlenecks.
Cassandra is designed to have peer-to-peer symmetric nodes, instead of master-slave nodes, to ensure there can never be a single point of failure. Cassandra automatically partitions data across all the nodes in the database cluster ( this setting is controlled by the administrator who determine what data will be replicated and how many copies of the data will be created)
3: Scalable
Cassandra is highly scalable database technology and a simplest cassandra cluster can contains as few as 2-3 nodes and also can grow upto 1000 nodes.
As per Apache cassandra Home Page , Some of the largest production deployments include Apple’s, with over 75,000 nodes storing over 10 PB of data, Netflix (2,500 nodes, 420 TB, over 1 trillion requests per day), Chinese search engine Easou (270 nodes, 300 TB, over 800 million requests per day), and eBay (over 100 nodes, 250 TB).
4: Durable
Since cassandra supports replication of data across datacenters, it is suitable for those applications that can’t afford to lose data, even when an entire data center goes down.
5: Elastic
Cassandra cluster is very elastic as new nodes can be added to cluster without any downtime or interruption to applications and thus increasing Read and write throughput increase linearly.
6: Distributed Writes
Within cassandra cluster, data can be read from and write to anywhere in the cluster at any time.
7: Flexible Schema:
With Cassandra, you don’t have to decide what fields you need in your records ahead of time. You can add and remove arbitrary fields on the fly.
Cassandra Architecture
The architecture of Cassandra greatly contributes to its being a database that scales and performs with continuous availability. As we discussed earlier that cassandra do not uses legacy RDBMS master-slave topology and instead it is a masterless “ring” distributed architecture that is elegant, and easy to setup and maintain.
Not having to distinguish between a Master and a Slave node allows you to add any number of machines to any cluster in any datacenter, without having to worry about what type of machine you need at the moment. Every server accepts requests from any client. Every server is identical.


Cassandra’s built-for-scale architecture means that it is capable of handling large amounts of data and thousands of concurrent users/operations per second, across multiple data centers. Cluster capacity can be increased on the fly without any configuration change.
Snitch
Since cassandra is a masterless technology, question comes in mind how the nodes in cassandra cluster knows about each other. Answer to this question is ‘Snitch’
Using snitch, nodes updates each other about which node is in which datacenter or which node is in which rack within a datacenter. Snitch is how the nodes in a cluster know about the topology of cluster.
There are various options for configuring snitch in a cluster including:
- Dynamic Snitching
- Simple Snitch
- Rack Inferring Snitch
- PropertyFileSnitch
- Gossipingpropertyfilesnitch
- EC2Snitch
- EC2 MultiRegion Snitch
You must configure a snitch when you create a cluster. All snitches use a dynamic snitch layer, which monitors performance and chooses the best replica for reading.
The default Simple Snitch do not recognize datacenter or rack information. Simple snitch can be only used with cluster that are within one datacenter.
The GossipingPropertyFileSnitch is recommended for production. It defines a node’s datacenter and rack and uses gossip for propagating this information to other nodes.
To learn more about snitch please read this Article from Edureka.
Gossip
Gossip is how node in cluster talks with each other. Every one second, each node communicate with up to 3 other nodes, exchanging information about itself and all the other nodes that it has information about.
The nodes exchange information about themselves and about the other nodes that they have gossiped about, so all nodes quickly learn about all other nodes in the cluster. A gossip message has a version associated with it, so that during a gossip exchange, older information is overwritten with the most current state for a particular node.


Gossip is the internal communication method for nodes in a cluster to talk to each other.
For external communication such as from an app to a cassandra database, CQL (cassandra query language) or Thrift is used.
On a lighter node, this sounds to me like Women’s gossip as they always talk about how other women is looking or which dress she worn yesterday, with whom she is hanging out etc 😀
Data distribution and replication
Data distribution is done through consistent hashing, to strive for even distribution of data across the nodes in a cluster. Rather than all of the rows of a table existing in only one node, the rows are distributed across the nodes in the cluster, in an attempt to evenly spread out the load of the table’s data.
To distribute rows across the node, a partitioner is used. A partitioner is a hash function that derives a token from the primary key of a row. The partitioner uses the token value to determine which nodes in the cluster receive the replicas of that row. The default partitioner in Cassandra is Murmur3.
To understand this consider below example of a home alarm system


Murmur3 takes the value in the first column or can take value from more than one column to generate a unique number between –263 – 263.
Let’s suppose Murmur3 generated below hashed values for data stored in first column.


Each node in the cluster has an endpoint value assigned to it. Each node is responsible then for values leading up to it including its value.


Now the question comes where do these endpoint values comes from?
There are couple of ways to do it:
1: Calculate the token range Manually
You can use below formula to generate the token range value. Below formula was used to generate token range for a 4 node cassandra cluster.
|
1 |
python -c 'print [str(((2**64 / number_of_tokens) * i) - 2**63) for i in range(number_of_tokens)]' |
If you have more than 4 nodes, replace 4 with number of nodes in your cluster. For example, to generate tokens for 6 nodes:
|
1 |
python -c 'print [str(((2**64 / 6) * i) - 2**63) for i in range(6)]' |
The command displays the token for each node:
|
1 2 |
[ '-9223372036854775808', '-6148914691236517206', '-3074457345618258604', '-2' , '3074457345618258600', '6148914691236517202' ] |
2: Murmur3 Calculator
Go to this website and navigate to Cassandra Token Calculator and select Murmur3Partitioner and in front of Number of nodes, enter value equal to number of nodes in your cluster and click on calculate Tokens to generate the endpoint values which will be assigned to each node.


Now these token values will be assigned to each one of the node.
The hashed value which was calculated earlier will be matched against the token value and then decision will be taken that on which node a particular row data will be stored.
Replication factor
Whenever a database is defined, a replication factor is defined along with. The replication factor specifies how many instances of the data there will be within a given database.
We can set replication factor as ‘1’ but it is always recommended to use a value greater than one so that in case a node goes down, there is at least one replica of the data and data is not lost with down node.
If in a 4 node cluster, replication factor is defined as 2, then there will be 2 nodes which will store same data. If replication factor is set to 4 then it means each node of cluster will have replica of the data which is stored on any node.
For e.g, if the replication factor for a database is 3, the -7456322128261119046 data will be written to 3 nodes and even if one node goes down, we will not lose data.


Replication Strategy
A replication strategy determines which nodes to place replicas on.
Two replication strategies are available:
- SimpleStrategy: Use only for a single datacenter and one rack. If you ever intend more than one datacenter, use the NetworkTopologyStrategy. SimpleStrategy places the first replica on a node determined by the partitioner. Additional replicas are placed on the next nodes clockwise in the ring without considering topology.
- NetworkTopologyStrategy: Highly recommended for most deployments because it is much easier to expand to multiple datacenters when required by future expansion. NetworkTopologyStrategy places replicas in the same datacenter by walking the ring clockwise until reaching the first node in another rack. It attempts to place replicas on distinct racks because nodes in the same rack often fail at the same time due to power, cooling, or network issues.
That’s it for this post.In next posts of this series we will learn how to install and configure casandra and we will also touchdown of administering and troubleshooting part.
I hope this post is informational to you. Feel free to share this on social media if it is worth sharing. Be sociable 






