

If you are a big data analyst, or build big data solutions for fast analytical queries, you are likely familiar with columnar storage technologies. The open source Parquet file format for HDFS saves space and powers query engines from Spark to Impala and more, while cloud solutions like Amazon Redshift use columnar storage to speed up queries and minimize I/O. Being a file format, Parquet is much more challenging to work with directly for real-time data ingest. For applications like IoT, time-series, and event data analytics, many developers have turned to NoSQL databases such as Apache Cassandra, due to their combination of high write scalability and the ease of using an idempotent, primary key-based database API. Most NoSQL databases are not designed for fast, bulk analytical scans, but instead for highly concurrent key-value lookups. What is missing is a solution that combines the ease of use of a database API, the scalability of NoSQL databases, with columnar storage technology for fast analytics.
Introducing FiloDB. Distributed. Versioned. Columnar.
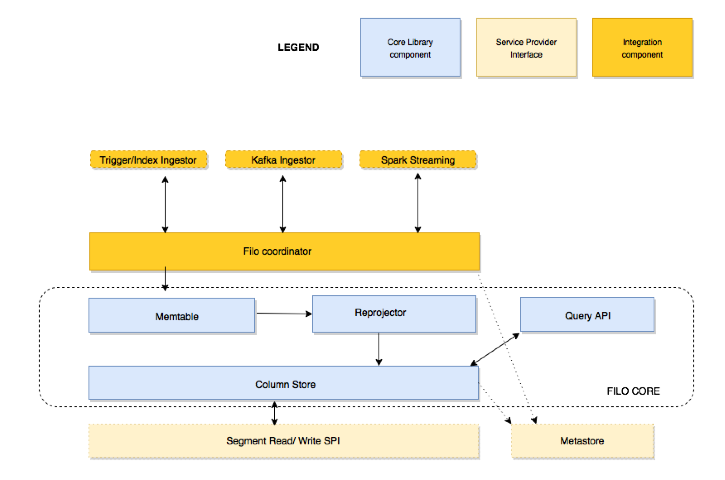
I am excited to announce FiloDB, a new open-source distributed columnar database from TupleJump. FiloDB is designed to ingest streaming data of various types, including machine, event, and time-series data, and run very fast analytical queries over them. In four-letter acronyms, it is an OLAP solution, not OLTP.
- Distributed - FiloDB is designed from the beginning to run on best-of-breed distributed, scale-out storage platforms such as Apache Cassandra. Queries run in parallel in Apache Spark for scale-out ad-hoc analysis.
- Columnar - FiloDB brings breakthrough performance levels for analytical queries by using a columnar storage layout with different space-saving techniques like dictionary compression. The performance is comparable to Parquet, and one to two orders of magnitude faster than Spark on Cassandra 2.x for analytical queries. For the POC performance comparison, please see the cassandra-gdelt repo.
- Versioned - At the same time, row-level, column-level operations and built in versioning gives FiloDB far more flexibility than can be achieved using file-based technologies like Parquet alone.
Your Database for Fast Streaming + Big Data
FiloDB is designed for streaming applications. Enable easy exactly-once ingestion from Apache Kafka for streaming events, time series, and IoT applications - yet enable extremely fast ad-hoc analysis using the ease of use of SQL. Each row is keyed by a partition and sort key, and writes using the same key are idempotent. Idempotent writes enables exactly-once storage of event data. FiloDB does the hard work of keeping data stored in an efficient and read-optimized, sorted format.
FiloDB + Cassandra + Spark = Lightning-fast Analytics
FiloDB leverages Apache Cassandra as its storage engine, and Apache Spark as its compute layer. Apache Cassandra is one of the most widely deployed, rock-solid distributed databases in use today, with very well understood operational characteristics. Many folks are combining Apache Spark with their Cassandra tables for much richer analytics on their Cassandra data than is possible with just the native Cassandra CQL interface. However, loading massive amounts of data from Cassandra into Spark can still be very slow, especially for analytics and ad-hoc queries such as averaging or computing the correlation between two columns of data. This is because Cassandra CQL tables stores data in a row-oriented manner. FiloDB brings the benefits of efficient columnar storage and the flexibility and richness of Apache Spark to the rock solid storage technology of Cassandra, speeding up analytical queries by up to 100x over Cassandra 2.x.
Easy Ingestion + SQL + JDBC + Spark ML
FiloDB uses Apache Spark SQL and DataFrames as the main query mechanism. This lets you run familiar SQL queries over your data, and easily connect tools such as Tableau to query your data, using Spark’s JDBC connector. At the same time, the full power of Spark is available for your data, including the machine learning MLlib library and GraphX for graph processing.
Ingesting data is also very easy through Spark DataFrames. This means you can easily ingest data from any JDBC data source, Parquet and Avro files, Cassandra tables, and much, much, more. This includes easily inserting data from Spark Streaming and Apache Kafka.
Simplify your Analytics Stack. FiloDB + SMACK for everything.
Use Kafka + Spark + Cassandra + FiloDB to power your entire Lamba architecture implementation. There is no need to implement a complex Lambda dual ingestion pipeline with both Cassandra and Hadoop! You can use the SMACK stack (Spark/Scala, Mesos, Akka, Cassandra, Kafka) for a much bigger portion of your analytics stack than before, reducing infrastructure investment.
What’s in the name?

I love desserts, and Filo dough is an essential ingredient. One can think of columns and versions of data as layers, and FiloDB wrapping the layers in a yummy high-performance analytical database engine.
Proudly built with the Typesafe Stack
FiloDB is built with the Typesafe reactive stack for high-performance distributed computing and asynchronous I/O - Scala, Spark, and Akka.
Come to the Talk at Cassandra Summit!
If you’d like to learn more, I encourage you to come on over to Cassandra Summit in Santa Clara, where I’ll be speaking about FiloDB and Spark and Cassandra, on Thursday September 24th at the Santa Clara Convention Center! Or feel free to reach out. The repo and more details such as the roadmap will be unveiled at the talk.





