
Apache Cassandra obviously can’t tell the future. It can only enable you to organize data storage (or at least make it as organized as it can get in a distributed system). But how good is Cassandra at it? Find all the needed details below so that Cassandra performance is not all Greek to you anymore.

Terms you may not know yet
Down below, our Cassandra specialists use quite a lot of specific terms that you may encounter for the first time. Here, you may find all these terms briefly explained.
Token is a somewhat abstract number assigned to every node of the cluster in an ascending manner. All the nodes form a token ring.
Partitioner is the algorithm that decides what nodes in the cluster are going to store data.
Replication factor determines the number of data replicas.
Keyspace is the global storage space that contains all column families of one application.
Column family is a set of Cassandra’s minimal units of data storage (columns). Columns consist of a column name (key), a value and a timestamp.
Memtable is a cache memory structure.
SSTable is an unchangeable data structure created as soon as a memtable is flushed onto a disk.
Primary index is a part of the SSTable that has a set of this table’s row keys and points to the keys’ location in the given SSTable.
Primary key in Cassandra consists of a partition key and a number of clustering columns (if any). The partition key helps to understand what node stores the data, while the clustering columns organize data in the table in ascending alphabetical order (usually).
Bloom filters are data structures used to quickly find which SSTables are likely to have the needed data.
Secondary index can locate data within a single node by its non-primary-key columns. SASI (SSTable Attached Secondary Index) is an improved version of a secondary index ‘affixed’ to SSTables.
Materialized view is a means of ‘cluster-wide’ indexing that creates another variant of the base table but includes the queried columns into the partition key (while with a secondary index, they are left out of it). This way, it’s possible to search for indexed data across the whole cluster without looking into every node.
Data modeling in Cassandra
Cassandra’s performance is highly dependent on the way the data model is designed. So, before you dive into it, make sure that you understand Cassandra’s three data modeling ‘dogmas’:
- Disk space is cheap.
- Writes are cheap.
- Network communication is expensive.
These three statements reveal the true sense behind all Cassandra’s peculiarities described in the article.
And as to the most important rules to follow while designing a Cassandra data model, here they are:
- Do spread data evenly in the cluster, which means having a good primary key.
- Do reduce the number of partition reads, which means first thinking about the future queries’ composition before modeling the data.
Data partitioning and denormalization
To assess Cassandra performance, it’s logical to start in the beginning of data’s path and first look at its efficiency while distributing and duplicating data.
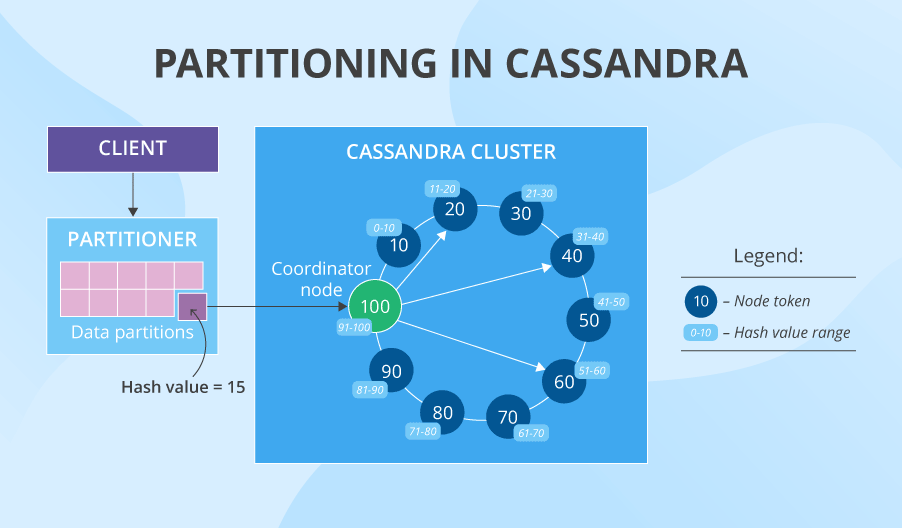
Partitioning and denormalization: The process
While distributing data, Cassandra uses consistent hashing and practices data replication and partitioning. Imagine that we have a cluster of 10 nodes with tokens 10, 20, 30, 40, etc. A partitioner converts the data’s primary key into a certain hash value (say, 15) and then looks at the token ring. The first node whose token is bigger than the hash value is the first choice to store the data. And if we have the replication factor of 3 (usually it is 3, but it’s tunable for each keyspace), the next two tokens' nodes (or the ones that are physically closer to the first node) also store the data. This is how we get data replicas on three separate nodes nice and easy. But besides that, Cassandra also practices denormalization and encourages data duplication: creating numerous versions of one and the same table optimized for different read requests. Imagine how much data it is, if we have the same huge denormalized table with repeating data on 3 nodes and each of the nodes also has at least 3 versions of this table.
Partitioning and denormalization: The downside
The fact that data is denormalized in Cassandra may seem weird, if you come from a relational-database background. When any non-big-data system scales up, you need to do things like read replication, sharding and index optimization. But at some point, your system becomes almost inoperable and you realize that the amazing relational model with all its joins and normalization is the exact reason for performance issues.
To solve this, Cassandra has denormalization as well as creates several versions of one table optimized for different reads. But this ‘aid’ does not come without consequence. When you decide to increase your read performance by creating data replicas and duplicated table versions, write performance suffers a bit because you can’t just write once anymore. You need to write the same thing n times. Besides, you need a good mechanism of choosing which node to write to, which Cassandra provides, so no blames here. And although these losses to the write performance in Cassandra are scanty and often neglected, you still need the resources for multiple writes.
Partitioning and denormalization: The upside
Consistent hashing is very efficient for data partitioning. Why? Because the token ring covers the whole array of possible keys and the data is distributed evenly among them with each of the nodes getting loaded roughly the same. But the most pleasant thing about it is that your cluster’s performance is almost linearly scalable. It sounds too good to be true but it is in fact so. If you double the number of nodes, the distance between their tokens will decrease by half and, consequently, the system will be able to handle almost twice as many reads and writes. The extra bonus here: with doubled nodes, your system becomes even more fault-tolerant.
The write
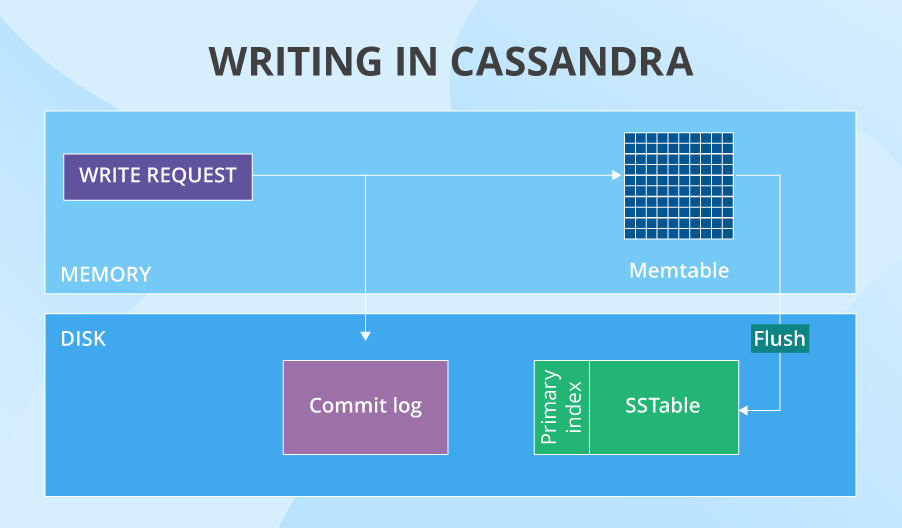
Write: The process
After being directed to a specific node, a write request first gets to the commit log (it stores all the info about in-cache writes). At the same time, the data gets stored in the memtable. At some point (for instance, when the memtable is full), Cassandra flushes the data from cache onto the disk – into SSTables. At the same moment, the commit log purges all its data, since it no longer has to watch out for the corresponding data in cache. After a node writes the data, it notifies the coordinator node about the successfully completed operation. And the number of such success notifications depends on the data consistency level for writes set by your Cassandra specialists.
Such a process happens on all nodes that get to write a partition. But what if one of them is down? There’s an elegant solution for it – hinted handoff. When the coordinator sees that a replica node is not responding, it stores the missed write. Then, Cassandra temporarily creates in the local keyspace a hint that will later remind the ‘derailed’ node to write certain data after it goes back up. If the node doesn’t recover within 3 hours, the coordinator stores the write permanently.
Write: The downside
Still, the write is not perfect. Here’re some upsetting things:
- Append operations work just fine, while updates are conceptually missing in Cassandra (although it’s not entirely right to say so, since such a command exists). When you need to update a certain value, you just add an entry with the same primary key but a new value and a younger timestamp. Just imagine how many updates you may need and how much space that will take up. Moreover, it can affect read performance, since Cassandra will need to look through lots of data on a single key and check whichever the newest one is. However, once in a while, compaction is enacted to merge such data and free up space.
- The hinted handoff process can overload the coordinator node. If this happens, the coordinator will refuse writes, which can result in the loss of some data replicas.
Write: The upside
Cassandra’s write performance is still pretty good, though. Here’s why:
- Cassandra avoids random data input having a clear scenario for how things go, which contributes to the write performance.
- To make sure that all the chosen nodes do write the data, even if some of them are down, there’s the above-mentioned hinted handoff process. However, you should note that hinted handoff only works when your consistency level is met.
- The design of the write operation involves the commit log, which is nice. Why? If a node goes down, replaying the commit log after it’s up again will restore all the lost in-cache writes to the memtable.
The read
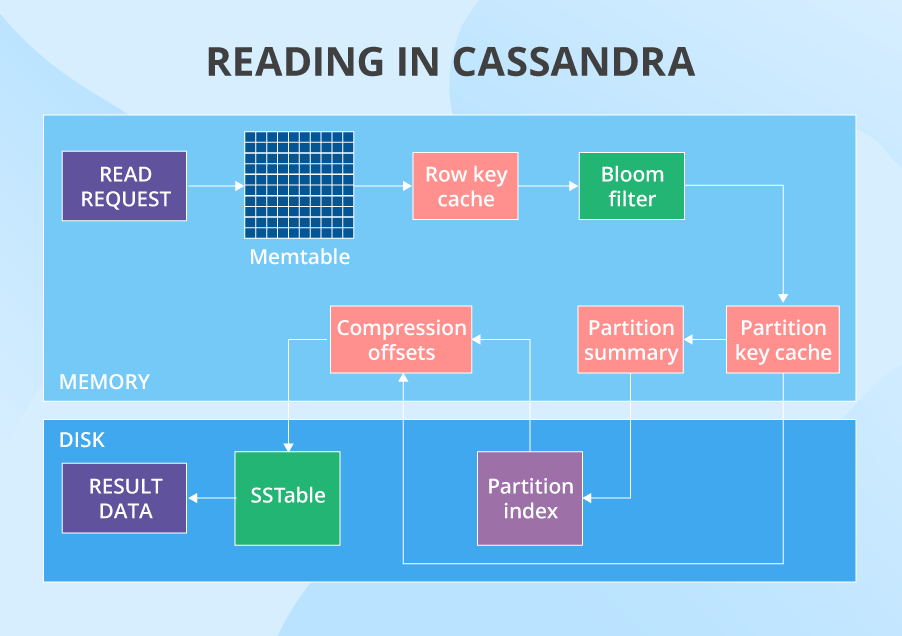
Read: The process
When a read request starts its journey, the data’s partition key is used to find what nodes have the data. After that, the request is sent to a number of nodes set by the tunable consistency level for reads. Then, on each node, in a certain order, Cassandra checks different places that can have the data. The first one is the memtable. If the data is not there, it checks the row key cache (if enabled), then the bloom filter and then the partition key cache (also if enabled). If the partition key cache has the needed partition key, Cassandra goes straight to the compression offsets, and after that it finally fetches the needed data out of a certain SSTable. If the partition key wasn’t found in partition key cache, Cassandra checks the partition summary and then the primary index before going to the compression offsets and extracting the data from the SSTable.
After the data with the latest timestamp is located, it is fetched to the coordinator. Here, another stage of the read occurs. As we’ve stated here, Cassandra has issues with data consistency. The thing is that you write many data replicas and you may read their old versions instead of the newer ones. But Cassandra doesn’t ignore these consistency-related problems: it tries to solve them with a read repair process. The nodes that are involved in the read return results. Then, Cassandra compares these results based on the “last write wins” policy. Hence, the new data version is the main candidate to be returned to the user, while the older versions are rewritten to their nodes. But that’s not all. In the background, Cassandra checks the rest of the nodes that have the requested data (because the replication factor is often bigger than consistency level). When these nodes return results, the DB also compares them and the older ones get rewritten. Only after this, the user actually gets the result.
Read: The downside
Cassandra read performance does enjoy a lot of glory, but it’s still not entirely flawless.
- All is fine as long as you only query your data by the partition key. If you want to do it by an out-of-the-partition-key column (use a secondary index or a SASI), things can go downhill. The problem is that secondary indexes and SASIs don’t contain the partition key, which means there’s no way to know what node stores the indexed data. It leads to searching for the data on all nodes in the cluster, which is neither cheap nor quick.
- Both the secondary index and the SASI aren’t good for high cardinality columns (as well as for counter and static columns). Using these indexes on the ‘rare’ data can significantly decrease read performance.
- Bloom filters are based on probabilistic algorithms and are meant to bring up results very fast. This often leads to false positives, which is another way to waste time and resources while searching in the wrong places.
- Apart from the read, secondary indexes, SASIs and materialized views can adversely affect the write. In case with SASI and secondary index, every time data is written to the table with an indexed column, the column families that contain indexes and their values will have to be updated. And in case with materialized views, if anything new is written to the base table, the materialized view itself will have to be changed.
- If you need to read a table with thousands of columns, you may have problems. Cassandra has limitations when it comes to the partition size and number of values: 100 MB and 2 billion respectively. So if your table contains too many columns, values or is too big in size, you won’t be able to read it quickly. Or even won’t be able to read it at all. And this is something to keep in mind. If the task doesn’t strictly require reading this number of columns, it’s always better to split such tables into multiple pieces. Besides, you should remember that the more columns the table has, the more RAM you’ll need to read it.
Read: The upside
Fear not, there are strong sides to the read performance as well.
- Cassandra provides excitingly steady data availability. It doesn't have a single point of failure, plus, it has data stored on numerous nodes and in numerous places. So, if multiple nodes are down (up to half the cluster), you will read your data anyway (provided that your replication factor is tuned accordingly).
- The consistency problems can be solved in Cassandra through the clever and fast read repair process. It is quite efficient and very helpful, but still we can’t say it works perfectly all the time.
- You may think that the read process is too long and that it checks too many places, which is inefficient when it comes to querying frequently accessed data. But Cassandra has an additional shortened read process for the often-needed data. For such cases, the data itself can be stored in a row cache. Or its ‘address’ can be in the key cache, which facilitates the process a lot.
- Secondary indexes can still be useful, if we’re speaking about analytical queries, when you need to access all or almost all nodes anyway.
- SASIs can be an extremely good tool for conducting full text searches.
- The mere existence of materialized views can be seen as an advantage, since they allow you to easily find needed indexed columns in the cluster. Although creating additional variants of tables will take up space.
Cassandra performance: Conclusion
Summarizing Cassandra performance, let’s look at its main upside and downside points. Upside: Cassandra distributes data efficiently, allows almost linear scalability, writes data fast and provides almost constant data availability. Downside: data consistency issues aren’t a rarity and indexing is far from perfect.
Obviously, nobody’s without sin, and Cassandra is not an exception. Some issues can indeed influence write or read performance greatly. So, you will need to think about Cassandra performance tuning if you encounter write or read inefficiencies, and that can involve anything from slightly tweaking your replication factors or consistency levels to an entire data model redesign. But this in no way means that Cassandra is a low-performance product. If compared with MongoDB and HBase on its performance under mixed operational and analytical workload, Cassandra – with all its stumbling blocks – is by far the best out of the three (which only proves that the NoSQL world is a really long way from perfect). However, Cassandra’s high performance depends a lot on the expertise of the staff that deals with your Cassandra clusters. So, if you choose Cassandra, nice job! Now, choose the right people to work with it.
Cassandra consulting and support by ScienceSoft
Feel helpless being left alone with your Cassandra issues? Hit the button, and we?ll give you all the help you need to handle Cassandra troubles.
Open our first aid kit





