
Lessons I Learned the First Time Around
Jun 12, 2015 · 9 min read
On a recent project, we decided that, instead of a standard RDBMS, we would use Cassandra. As a developer who, throughout my career, has made plentiful use of all the standard RDBMSs in use by web applications today, I was excited to learn something new. Not only was Cassandra a new database tool to learn, it presented an entirely new paradigm, a new way to think about and look at the database. If only I had realized that before starting, perhaps the process of learning would have gone a bit smoother.
This is not a detailed account of what Cassandra is, what makes it special, unique or a better choice for our project compared with a more relational database. There are already far too many of those articles available, and if that is what you are trying to learn, I recommend you spend several hours, maybe even days, reading those articles before you jump right in on a project that is in progress.
However, it would be irresponsible to discuss the challenges of using Cassandra after over nine years using relational databases, without a quick word about what Cassandra is. Cassandra is a NoSQL database. That term is used a lot and often misunderstood to mean “a database that does not use SQL”. That is not accurate. A more precise interpretation would be “Not Only SQL”, the details of which I will touch on later, but suffice to say that this boils down to the fact that Cassandra, and other NoSQL databases, are not just another implementation of tables, columns, and rows. Cassandra is also a distributed, “eventually consistent”, always available database. Distributed means that your database can be hosted on more than one server, in more than one datacenter, in more than one country; each “Write” operation will be performed on a single node in your cluster and then replicated to the entire cluster. Eventually consistent means that after you write data to a node, that node will tell all the other nodes in the cluster to update with the same data, but there’s no guarantee that the data you wrote in one node will be immediately available to the next operation that queries that data.
This can be tuned, but the default behavior is to accept the idea that the data will be replicated “eventually”. Always available is another key characteristic of Cassandra, dictating that if one node in the cluster goes down, no matter which one it is, the rest of the cluster will pick up the slack immediately. All nodes have the same role and work together as a team. There is no “boss”, “supervisor”, or “god” node, just the cluster getting work done.
If you find yourself asking a bunch of questions at this point (“Why does it do that?”, “How is that better than PostgreSQL?”) I encourage you to take the time to go read a proper Introduction or “Getting Started” article about Cassandra. There is lots to know about it, but I promised to tell you instead about the lessons I learned.
Cassandra is NOT Relational
This might seem obvious or even repetitive, but you would do yourself well to remind yourself of this often while learning Cassandra: it is not a relational database. The most important lesson I can share with anyone who is learning a new technology or a new framework is that you should resist the urge to carry-over best practices and understandings of other, more familiar frameworks for the sake of feeling more comfortable. This was particularly challenging in learning Cassandra because of the default client language, CQL (Cassandra Query Language).
CQL will look very familiar to someone who is well-versed in relational SQL, in fact many times it will be downright indistinguishable. CQL has syntax like “CREATE TABLE”, “INSERT INTO”, “CREATE INDEX”, etc which will make you think “I’ve done this before while working with MySQL! I can just do the same thing here!” NO YOU CANNOT. As tempting as it will inevitably be, allowing the similar syntax to lead you to think of your Cassandra keyspace as synonymous with your old MySQL database, is no different than using your VW Golf to tow your horse trailer. Sure, the pieces might all fit, there’s a steering wheel and a gas and a brake pedal, but it’s the wrong tool and if you use it the wrong way, you will break it.
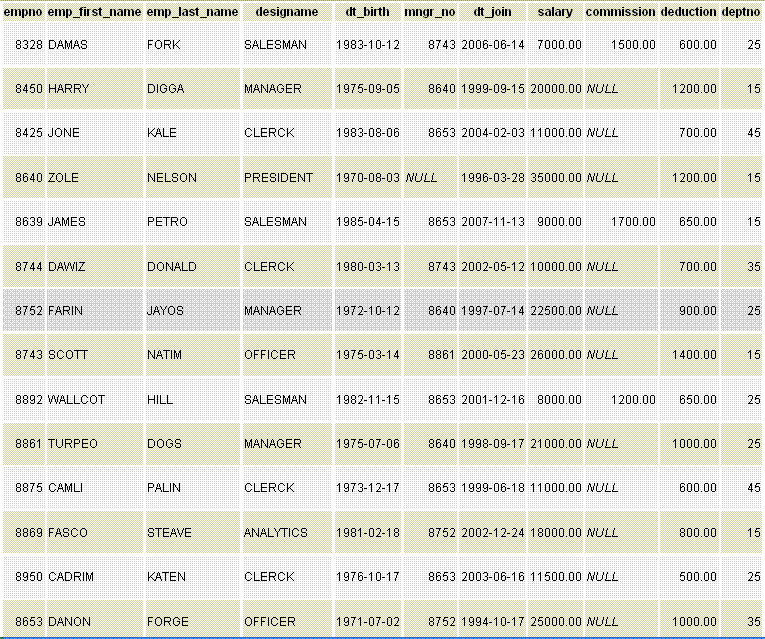
The real distinction is how Cassandra stores your data. In the relational world, your data is all stored in rows and columns, making up tables. Your table is rectangular (meaning that every row has the same number of columns) and it has a Primary Key, which can be one or more columns, and each row can be uniquely identified by that Primary Key. The database system will do what it can to store the rows of your table contiguously, so scans are efficient, and you can use Indexes on your tables to help queries quickly find the data you are looking for. Your tables can be visualized like this:
In contrast, despite the impression you may get from CQL, Cassandra does not use the same simple, two-dimensional storage scheme. Cassandra is based on two philosophies that distinctly differ from relational databases: BigTable and Wide Rows. BigTable was a white paper written at Google that inspired the structure of data as well as the distributed nature in use by Cassandra. Wide Rows is an idea that I will describe a little more later, but can be thought of as allowing Cassandra to store rows that are variable width, and also incredibly wide, up to 2 billion columns!!
Cassandra bases storage on the first part of the primary key, which is also known as the “partition key”. When querying a record in Cassandra, you are expected to query based on the partition key. Cassandra uses the partition key very much like how many languages use the key of a hash, making it efficient to read and write data based on that key. A Cassandra table can be visualized more like this:
If there is one lesson to learn about Cassandra, it’s that it is not relational and should not be treated that way. There are no foreign keys and many tables can get away without a dedicated integer or UUID primary key field; since data is partitioned from a hashed value of the primary key fields, there is little to no reason you can’t just use a text field as your primary key. But that gets more into….
Data Modeling
When you are designing the schema for your relational database, the primary thought on your mind is “What’s the best way to store this data?”. But with Cassandra, your dominant concern should be “How am I going to query this data?” Given Cassandra’s data structure, writes are incredibly cheap, but reads are expensive. Since there are no joins in Cassandra, if you need data from more than one table, you are going to have to perform more than one read query. But that’s the relational way to do things. In Cassandra, we prefer denormalization.
Denormalization is the practice of preferring to duplicate data in all the places you may need to read it, rather than having a single source of truth that can be found based on ID fields on other objects. So if you are building an HR database and you want to know the name of an employee’s manager, store that manager’s name on the Manager record, but also on the Employee record. Remember, writing that data is cheap, reading it is not so much.
The second consideration of data modeling that I want to point out is the concept of Wide Rows. This concept is far beyond the scope of this article. But the big picture is that you can have a single row of data that grows in width as more data is written to the database. This is accomplished via compound primary keys and the conventional example is a time series table, like storing the temperature for weather stations once every minute. Compound primary keys are made up of the partition key and the clustering keys. The partition key, aka the “row key”, is the value that will be hashed to tell Cassandra where this row is stored. When you use a clustering key, instead of inserting a whole new row for each record, new records will be stored as a new column on the same old row. What the heck does that mean?!
Using the weather station example, let’s suppose you have several weather stations and you want to record the temperature at each weather station once per minute. Your primary key might have two parts: 1) The row key is a UUID identifying your weather station and, 2) The clustering key, which is the timestamp of the reading. So when you insert the very first record for Weather Station A, Cassandra will create a new row, with the weather station as the row key. The next record you insert will be stored on the same row since your primary key has a clustering key, and the new record will be inserted as a new column, where the name of the column is the time of the reading, and the value in that column is the temperature that was read.
This is made possible because Cassandra allows rows to have up to 2 billion columns. And since all the temperature readings for a given weather station are stored in the same row, your reads will even be super efficient. For a more detailed discussion, see this article on PlanetCassandra.
Indexing
Cassandra has yet another feature that sounds like something you might find in an RDBMS, but since the implementation is so different, it cannot be directly translated. Whereas you can add an index to a table in an RDBMS to make querying on any arbitrary field quicker, Cassandra’s table index, or more accurately “Secondary Index”, is far less effective. It serves largely the same purpose. But for high cardinality or low cardinality fields, it’s an incredibly inefficient tool. For review, cardinality is the level of distinct values a field is expected to have. So a gender field has low cardinality, as there are only two possible values, and email address has very high cardinality, since, in theory, everyone will have a unique email address. Either of these fields would be a poor choice for a secondary index.
You may be asking, “So how the heck am I supposed to query a table of users by their email address?” Great question! Assuming email address is not your partition key (which would be a valid option, but not for the sake of this example), the best way to query by email address is to create a new table. Sounds crazy, but as I’ve said, writes are cheaper than reads and we strive for denormalization. So if you have a “users” table with a bunch of fields and you are planning on querying by email address, create a new table called“users_by_email”, where the partition key is the email address. That table should also have all the fields that you will expect to need when you query by email address, that way it’s just one efficient read.
The trick, of course, comes when writing data. You have to make sure, whether you are inserting new data or updating existing data, to update the “users_by_email” table as well as the “users” table, or your data models will become out of sync.
Excelsior!
Now you know everything you need to become a Cassandra expert. You should expect to create the greatest Cassandra databases known to man and you will cure terrible tropical diseases.
Actually, none of that is true. I cannot overemphasize, this is only some of the lessons I have learned in my first month or so of using Cassandra. There is so much more to learn and surely these lessons will be supplemented, updated or maybe even proven completely bogus (geez, I hope not). The point being that Cassandra is a great tool. If you are in a position to learn it, by all means, do so. But remember, it’s not the same as migrating from MySQL to PostgresSQL; it is a giant shift in the way to see and use your database, so never let yourself become too comfortable with applying your hard-earned wisdom of the RDBMS world into the NoSQL world of Cassandra.
As always, for every job you have the option of which tools to use; make that choice for the right reasons. Once you pick your tool, use it the way it is meant to be used, otherwise you are going to break it!










