In this blog, I will talk about chaos engineering on Cassandra with Litmus. Before jumping in, let's do a quick recap on Litmus. Litmus is a framework for practicing Chaos Engineering in cloud-native environments. Litmus provides a chaos-operator, a large set of chaos experiments in its hub, detailed documentation, quick Demo, and a friendly community.
Apache Cassandra is a free and open-source, distributed, wide column store, NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers robust support for clusters spanning multiple datacenters with asynchronous masterless replication allowing low latency operations for all clients. Cassandra's support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
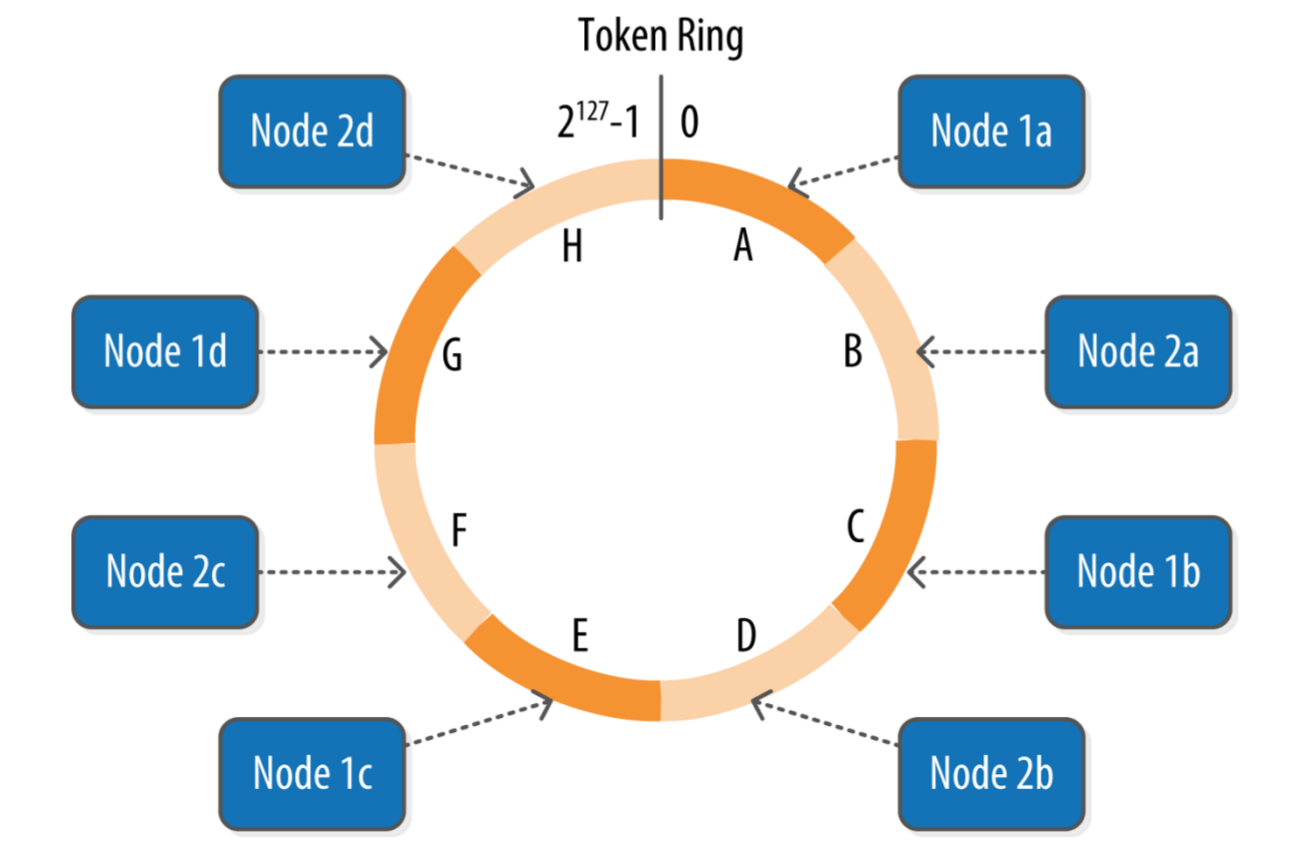
Cassandra is using Consistent Hashing, which is a distributed hashing scheme that operates independently of the number of servers or objects in a distributed hash table by assigning them a position on an abstract circle, or hash ring. This allows servers and objects to scale without affecting the overall system. Cassandra uniformly distributes the load over the Cassandra ring and re-distribute the load when the Cassandra Statefulset scales up/down.
With Kubernetes popularity skyrocketing and the adoption of Apache Cassandra growing as a NoSQL database well-suited to matching the high availability and scalability needs of cloud-based applications, it should be no surprise that more developers are looking to run Cassandra databases on Kubernetes. However, many devs are finding that doing so is relatively simple to get going with, but considerably more challenging to execute at a high level. We will discuss the installation part later in this blog.
On the positive side, Kubernetes helpfully offers StatefulSets — workload API objects that can be used to manage stateful applications. StatefulSets provide the requisite components to establish stable and unique network identifiers, stable persistent storage, smooth and ordering deployment and scaling (as well as deletion and termination), and automated rolling updates.

Distribution of load over the ring
Why do we need chaos engineering on Cassandra?
As Cassandra is using consistent hashing and maintaining the Cassandra ring to distribute the load uniformly. If the number of replicas will scale up/down, the load will be redistributed. But we always have a few questions in our mind:
- Does load redistribution always happen with 0 probability of failure in scale-up/down?
- How will it behave if the one/multiple replicas of the Cassandra Statefulset are killed?
- Is it resilient even if the rate of replica deletion is very high?
In the age of data evolution, data is very important and everyone is looking for a setup where the probability of downtime is least as possible. Here the chaos engineering comes into play. It will help you to find out all the corner cases of failure before they actually happen and if you really believe in "Prevention is better than cure" then the best real-life example award goes to chaos engineering. It can be used to test the resiliency of the Cassandra stateful set. As of now, we have a Cassandra-pod-delete experiment to test the case where one of the replicas of Cassandra Statefulset is deleted. More use-cases/experiments will be added soon.
Now that we know the basics of a Cassandra statefulset on Kubernetes, let us execute a chaos experiment to kill one of the replicas of Cassandra while the load is distributed on all the replicas over the Cassandra ring & verify whether the load is redistributed. This example intends to introduce the user to the steps involved in carrying out a chaos experiment using Litmus.
Pre-Requisites
- A (preferably) multi-node Kubernetes cluster. Ensure you are in the Kubernetes-admin context to setup RBAC for the various components involved.
Chaos Experiment Approach
The following steps are performed automatically upon execution of the Chaos Experiment:
An external liveness pod will be created, which will ensure the liveness of Cassandra statefulset during chaos execution. It is continuously running the liveness cycles of cqlsh commands. Liveness cycle stands for a set of cqlsh operations (create keyspace, create the table, insert data in the table, delete the tables, delete the keyspaces). It is running a webserver container as a side cart, which is exposing the status of the liveness cycle (cycleInProgress or cycleCompleted). The experiment looks for the status of the webserver service and cleans up the liveness deployment at the end of the cycle. In case of a timeout, the liveness container terminates ungracefully with an exception.
It will ensure that the load is distributed across all the replicas on the Cassandra ring before and after the chaos injection. It ensures that the load is re-distributed across all available replicas after every kill. In case if the load is not distributed on any of the available replicas, this check will be failed.
In its default mode, the experiment derives the random single/multiple replicas of Cassandra statefulset, performs a pod kill (delete), and checks the liveness and load distribution on the Cassandra ring across all replicas, which implies that the Cassandra statefulset remains alive and load redistribution takes place after every kill. If this is true, the experiment verdict is set to “pass,” indicating the current statefulset is tolerant to pod-failures. A terminated statefulset sets the verdict to “fail” and implies that the statefulset is not resilient enough, demanding a closer inspection.
Hypothesis
- Upon killing the replica of Cassandra statefulset, the load will be re-distributed over the Cassandra ring.
- After the deletion of the replica, the new replica will be created by the replica controller to maintain the desired count of the available replicas.
Preparing the Testbed
Setup the Cassandra Cluster
We are going to discuss two approaches to set up the Cassandra cluster quickly.
a) This approach will guide you to set up a Cassandra cluster in AWS EKS with OpenEBS as a storage orchestration tool.
Follow the following tutorial to setup the cluster Setup Cassandra Cluster on EKS.
b) This approach will guide you to set up the Cassandra cluster in Minikube. We can follow the underlying steps to set up the Cassandra cluster.
Creating the headless service for Cassandra which is used for DNS lookups between Cassandra Pods and clients within your cluster:
root@demo:~# cat <<EOF > cassandra-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: cassandra
name: cassandra
spec:
clusterIP: None
ports:
- port: 9042
selector:
app: cassandra
EOF
root@demo:~# kubectl create -f cassandra-service.yaml -n cassandra
service/cassandra created
Validation of Cassandra service:
root@demo:~# kubectl get svc cassandra -n cassandra
The response is:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cassandra ClusterIP None <none> 9042/TCP 45s
If you don't see a Service named Cassandra, that means creation failed.
The StatefulSet manifest included below, creates a Cassandra ring that consists of three Pods.
Note: This example uses the default provisioner for Minikube. Please update the following StatefulSet for the cloud you are working with.
root@demo:~# cat <<EOF > cassandra-sts.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: cassandra
labels:
app: cassandra
spec:
serviceName: cassandra
replicas: 3
selector:
matchLabels:
app: cassandra
template:
metadata:
labels:
app: cassandra
spec:
terminationGracePeriodSeconds: 1800
containers:
- name: cassandra
image: gcr.io/google-samples/cassandra:v13
imagePullPolicy: Always
ports:
- containerPort: 7000
name: intra-node
- containerPort: 7001
name: tls-intra-node
- containerPort: 7199
name: jmx
- containerPort: 9042
name: cql
resources:
limits:
cpu: "500m"
memory: 1Gi
requests:
cpu: "500m"
memory: 1Gi
securityContext:
capabilities:
add:
- IPC_LOCK
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- nodetool drain
env:
- name: MAX_HEAP_SIZE
value: 512M
- name: HEAP_NEWSIZE
value: 100M
- name: CASSANDRA_SEEDS
value: "cassandra-0.cassandra.default.svc.cluster.local"
- name: CASSANDRA_CLUSTER_NAME
value: "K8Demo"
- name: CASSANDRA_DC
value: "DC1-K8Demo"
- name: CASSANDRA_RACK
value: "Rack1-K8Demo"
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
readinessProbe:
exec:
command:
- /bin/bash
- -c
- /ready-probe.sh
initialDelaySeconds: 15
timeoutSeconds: 5
# These volume mounts are persistent. They are like inline claims,
# but not exactly because the names need to match exactly one of
# the stateful pod volumes.
volumeMounts:
- name: cassandra-data
mountPath: /cassandra_data
# These are converted to volume claims by the controller
# and mounted at the paths mentioned above.
# do not use these in production until ssd GCEPersistentDisk or other ssd pd
volumeClaimTemplates:
- metadata:
name: cassandra-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: fast
resources:
requests:
storage: 1Gi
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast
provisioner: k8s.io/minikube-hostpath
parameters:
type: pd-ssd
EOF
root@demo:~# kubectl create -f cassandra-sts.yaml -n cassandra
statefulset.apps/cassandra created
storageclass.storage.k8s.io/fast created
Validating the Cassandra StatefulSet
root@demo:~# kubectl get statefulset cassandra -n cassandra
The response should be similar to:
NAME DESIRED CURRENT AGE
cassandra 3 0 13s
root@demo:~# kubectl get pods -l="app=cassandra" -n cassandra
It can take several minutes for all three Pods to deploy. Once they are deployed, the same command returns output similar to:
NAME READY STATUS RESTARTS AGE
cassandra-0 1/1 Running 0 10m
cassandra-1 1/1 Running 0 9m
cassandra-2 1/1 Running 0 8m
Step-3: Run the Cassandra nodetool inside the first Pod, to display the status of the ring.
kubectl exec -it cassandra-0 -- nodetool status
The response should look something like:
Datacenter: DC1-K8Demo
======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.17.0.5 83.57 KiB 32 74.0% e2dd09e6-d9d3-477e-96c5-45094c08db0f Rack1-K8Demo
UN 172.17.0.4 101.04 KiB 32 58.8% f89d6835-3a42-4419-92b3-0e62cae1479c Rack1-K8Demo
UN 172.17.0.6 84.74 KiB 32 67.1% a6a1e8c2-3dc5-4417-b1a0-26507af2aaad Rack1-K8Demo
Setup the Litmus Infrastructure
root@demo:~# kubectl apply -f https://litmuschaos.github.io/pages/litmus-operator-v1.6.0.yaml
namespace/litmus created
serviceaccount/litmus created
clusterrole.rbac.authorization.k8s.io/litmus created
clusterrolebinding.rbac.authorization.k8s.io/litmus created
deployment.apps/chaos-operator-ce created customresourcedefinition.apiextensions.k8s.io/chaosengines.litmuschaos.io created
customresourcedefinition.apiextensions.k8s.io/chaosexperiments.litmuschaos.io created
customresourcedefinition.apiextensions.k8s.io/chaosresults.litmuschaos.io created
kubectl apply -f https://raw.githubusercontent.com/litmuschaos/pages/master/docs/litmus-admin-rbac.yaml
root@demo:~# kubectl apply -f https://hub.litmuschaos.io/api/chaos/1.6.0?file=charts/cassandra/cassandra-pod-delete/experiment.yamln litmus
chaosexperiment.litmuschaos.io/cassandra-pod-delete created
root@demo:~# kubectl annotate sts/cassandra litmuschaos.io/chaos="true" -n cassandra
statefulset.apps/cassandra annotated
Run the Chaos Experiment
root@demo:~# cat <<EOF > cassanddra-chaos.yaml
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: cassandra-chaos
namespace: litmus
spec:
appinfo:
appns: ‘'cassandra’
applabel: 'app=cassandra'
appkind: 'statefulset'
annotationCheck: 'true'
engineState: 'active'
chaosServiceAccount: litmus-admin
monitoring: false
jobCleanUpPolicy: 'delete'
experiments:
- name: cassandra-pod-delete
spec:
components:
Env:
- name: TOTAL_CHAOS_DURATION
value: '15'
- name: CHAOS_INTERVAL
value: '15'
- name: FORCE
value: 'false'
- name: CASSANDRA_SVC_NAME
value: 'cassandra'
- name: KEYSPACE_REPLICATION_FACTOR
value: '3'
- name: CASSANDRA_PORT
value: '9042'
- name: CASSANDRA_LIVENESS_CHECK
value: ''
EOF
root@demo:~# kubectl apply -f cassandra-chaos.yaml -n litmus
chaosengine.litmuschaos.io/cassandra-chaos created
Watch the pods on the app namespace (cassandra) to view the chaos actions in progress.
watch -n 1 kubectl get pods -n cassandra
Look out for the following events.
- The experiment job, as part of the experiment execution,
launches a liveness pod (cassandra-liveness) that runs few cqlsh queries (create keyspaces, create tables, data insertion, and cleanup of table & keyspaces) running
as separate containers of the same pod.
-
The liveness pod is failed if it is unable to run cqlsh commands(Cassandra is unavailable). View
the cassandra-liveness pod logs during the pod-delete to verify the Uninterrupted availability of Cassandra statefulset.
kubectl logs -f cassandra-liveness -n litmus
View the verdict (spec.experimentStatus.verdict)of the cassandra-pod-delete chaos experiment to check whether the Cassandra cluster is resilient to the pod-delete.
root@demo:~# kubectl describe chaos result cassandra-chaos-cassandra-pod-delete -n litmus
Name: cassandra-chaos-cassandra-pod-delete
Namespace: litmus
Labels: chaosUID=22d5ba06-1fe8-4b01-bdbb-6246e1cdb2c9
type=ChaosResult
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"litmuschaos.io/v1alpha1","kind":"ChaosResult","metadata":{"annotations":{},"labels":{"chaosUID":"22d5ba06-1fe8-4b01-bdbb-62...
API Version: litmuschaos.io/v1alpha1
Kind: ChaosResult
Metadata:
Creation Timestamp: 2020-07-16T12:28:00Z
Generation: 10
Resource Version: 20451
Self Link: /apis/litmuschaos.io/v1alpha1/namespaces/litmus/chaosresults/cassandra-chaos-cassandra-pod-delete
UID: 32ea5093-47ee-41d8-bc34-e513edb46660
Spec:
Engine: cassandra-chaos
Experiment: cassandra-pod-delete
Status:
Experimentstatus:
Fail Step: N/A
Phase: Completed
Verdict: Pass
Events: <none>
Conclusion
The Cassandra chaos experiments are a good way to determine a potential breach of SLAs in terms of data consistency, performance & timeouts due to unexpected replica-kill. It will boost the confidence of the developers for those use-cases for which their setup returns a positive/passed result. In the future even if that chaos happens naturally(finger crossed) then the developers don’t have to worry. They are already trained with chaos management skills as they are chaos engineers/warriors after the adoption of chaos engineering practices.
Do try this experiment & let me know your findings!
Are you an SRE or a Kubernetes enthusiast? Does Chaos Engineering excite you? Join Our Community #litmus channel in Kubernetes Slack
Contribute to LitmusChaos and share your feedback on Github
If you like LitmusChaos, become one of the many stargazers here
Litmus helps Kubernetes SREs and developers practice chaos engineering in a Kubernetes native way. Chaos experiments are published at the ChaosHub (https://hub.litmuschaos.io). Community notes is at https://hackmd.io/a4Zu_sH4TZGeih-xCimi3Q
View on GitHub