

TL;DR The future of indexing in Apache Cassandra is now GA in Astra, DataStax Enterprise 6.8.3 and soon in Apache Cassandra™.
DataStax is pleased to announce Storage-Attached Indexing (SAI), a highly scalable, globally-distributed index for Apache Cassandra™ now available on Astra and DataStax Enterprise (DSE).
Try Storage-Attached Indexing on Astra via the interactive scenario here.
Developers can use relational WHERE patterns that leverage user-expected database indexing capabilities for Apache Cassandra. SAI gives architects an efficient and simpler filtering capability than Cassandra’s current indexing or bolt-on search solutions. SAI solves the challenges Cassandra users faced in data modeling, query flexibility, and operations.
To explain this better, here’s an example. Assuming a simple table structure of-
CQL
CREATE TABLE demo.personnel (id int, firstname text, lastname text, age int, employee_start_date date, PRIMARY KEY (id) );
The following sample SELECT query in Cassandra was invalid before SAI, because it doesn’t reference the primary key.
CQL
SELECT firstname, lastname FROM demo.personnel WHERE age > 30
Though, now with SAI, the above sample query is not only valid, but it’s fast, and fast at scale!
Developers and architects building mission-critical, modern apps with breakthrough confidence, scalability, performance, and availability choose Cassandra because of its ability to scale to any workload across bare-metal, multi-cloud, hybrid, and everything in between. The flexibility to write code once and then deploy at scale with automated operations changes the costs associated with code-driven scaling. Even though Cassandra is great at ingesting data, it has a strict query pattern that limits developers who are used to relational databases, causing elongated development cycles and delayed time to market. Not anymore, SAI enables database indexing capabilities for Apache Cassandra at global scale.
Operators/DBAs feel confident supporting mission critical applications running on Cassandra because of zero downtime, and the less time it requires for them to maintain uptime and performance SLAs. With SAI, Operators have even less to worry about because operations associated with scaling and backup and restore have become more streamlined with SAI compared to bolt on indexing solutions.
What’s Available Today?
Not only is DataStax releasing SAI as a generally available feature for Astra and DSE users today in DSE 6.8.3, DataStax has also submitted the Apache CEP to bring this functionality to the Apache version of Cassandra.
Here’s the functionality that’s supported with this GA release of SAI.
| Feature | Available Now | Planned for Future |
|---|---|---|
| Query Operators | =, <, >, <=, >= (Numerics); CONTAINS, CONTAINS Key, CONTAINS VALUE, = (Strings) | OR, IN, LIKE, Geospatial |
| Apache Cassandra Types | ASCII, BIGINT, DATE, DECIMAL, DOUBLE, FLOAT, INT, INET SMALLINT, TEXT, TIME, TIMESTAMP, TIMEUUID, TINYINT, UUID, VARCHAR, VARINT, Collection types | Specialized Type, blob, counter and Geospatial Types |
| Fields Available for Indexing | Primary Key and Non Key Fields | |
| Backup/Restore | Yes | |
| Observability | Opscenter, Grafana, Virtual Tables | |
| Zero-Copy Streaming | Yes | |
| Tokenization | No | Exploring |
| Sorting | No | Exploring |
| Geospatial Filtering | No | Exploring |
| Security | All Authentication and Authorization, TDE |
Getting Started
Getting started with the Storage-Attached Indexing is easy:
Assuming the following table:
CQL
CREATE TABLE demo.personnel (id int, firstname text, lastname text, age int, employee_start_date date, PRIMARY KEY (id));
Here’s how you create Storage-Attached Index:
CQL
CREATE CUSTOM INDEX ON demo.personnel (lastname)
USING 'StorageAttachedIndex'
WITH OPTIONS = {'case_sensitive': false, 'normalize': true };
And that’s it! You’re now ready to query the data you’ve just indexed. Under the hood, the index is optimized based on the data type of the selected column. For example, numeric types are optimized for range queries. We choose the right index implementation so you don’t have to think about it.
The SAI documentation has a Getting Started guide to follow to help you learn this great new index.
Design
Storage-Attached Indexing is built on the best practices from existing Cassandra index solutions as well as the best-of-breed distributed indexing algorithms that exist in common bolt-on distributed index and search solutions. SAI is deeply integrated with the storage engine of Apache Cassandra, which is why we call this Storage-Attached Indexing. It does not abstractly index tables but indexes Cassandra’s in memory Memtable and on-disk SSTable data structures as data is written. SAI intelligently filters results both in-memory and on-disk data structures at read time.
SAI introduces very little operational complexity on top of the core database. From snapshot creation to schema management to data expiration, SAI integrates tightly with the capabilities and mechanisms already provided by the core database. Storage-Attached Indexing is also fully compatible with zero-copy streaming. This means that as you bootstrap or decommission nodes, the indexes are fully streamed with the SSTables and do not have to be serialized or rebuilt on the receiving node’s end.
SAI doesn’t introduce any special configurations or “magic” settings to achieve performance. Standard Cassandra tuning techniques will continue to work. For example, if you have strict read latency requirements, it’s important to tune compaction parameters to make sure Cassandra’s compaction can stay up and keep the number of SSTables nice and low. The same techniques that you’d use to tune compaction of non-indexed tables apply equally to tables indexed using SAI.
Total Cost of Ownership
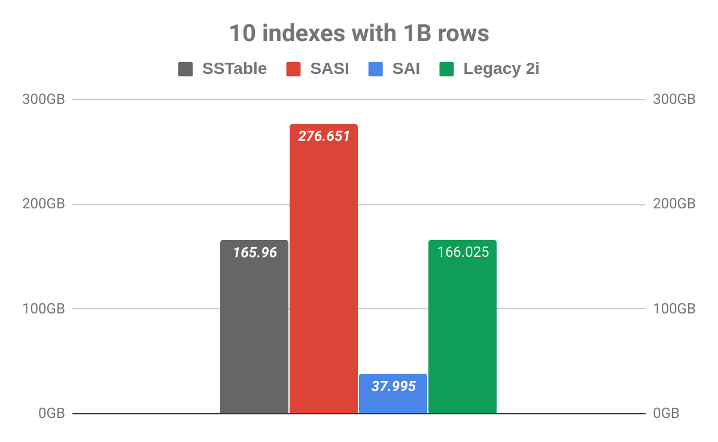
SAI requires significantly lower disk usage compared to other native or bolt-on Cassandra index solutions. This chart shows the on disk footprint for SAI compared to Cassandra SASI and Secondary Indexes. Unlike SASI, SAI doesn’t create ngrams for every term, thus saving a ton of disk space. Compared to Secondary Indexes, SAI doesn’t require duplicating an entire table with a new partition key.
Performance
In initial testing, we’ve seen significant performance improvements for mutations (Cassandra insert, update, delete statements) for SAI over other native Cassandra indexing solutions. In general terms, users should expect to achieve about 40% better throughput when using SAI compared to Secondary Indexes and about 230% better latency. SAI is slightly faster for read operations compared to Secondary Indexes. You should get better performance plus more functionality with SAI compared to other index solutions for Cassandra.
What are We Working on Next?
We worked hard to lay out a solid foundation with SAI so we can focus on developing new features. Our priority over the next couple of months is to:
- Bring this to open source Apache Cassandra through the CEP process
- Keep pushing the boundaries for Cassandra indexing with global ordering, tokenization, and geospatial support.
We're Here for You!
Storage Attached Indexing has been a passion project for DataStax’s engineering team who adopted a mission to solve the challenges Cassandra users face in data modeling, operations, and query flexibility. In particular, because SAI allows users to filter data on any field in a table, users no longer have to create tables to match queries, a common Cassandra best practice that causes lots of data duplication and developer confusion. Developers can now simply create a table, index fields with SAI, and query the data they need.
After years of R&D on various distributed indexing engines and years of knowledge gained from solving some of the most complex distributed data problems, DataStax has solved the challenge of flexibly reading data from Cassandra thanks to this new distributed index..
We hope you like SAI as much as we do. If you have any questions or feedback, please email us directly at product.feedback@datastax.com. Our engineering team is ready and happy to help, take feedback, and have conversations.




