
We will discuss two parts here; first, the database design internals that may help you compare between database’s, and second the main intuition behind auto-sharding/auto-scaling in Cassandra, and how to model your data to be aligned to that model for the best performance.
Part 1: Database Architecture — Master-Slave and Masterless and its impact on HA and Scalability
There are two broad types of HA Architectures Master -slave and Masterless or master-master architecture.
Here is an interesting Stack Overflow QA that sums up quite easily one main trade-off with these two type of architectures.
Q. -I’ve heard about two kind of database architectures.
master-master and master-slave
Isn’t the master-master more suitable for today’s web cause it’s like Git, every unit has the whole set of data and if one goes down, it doesn’t quite matter.
A.- There’s a fundamental tension:
One copy: consistency is easy, but if it happens to be down everybody is out of the water, and if people are remote then may pay horrid communication costs. Bring portable devices, which may need to operate disconnected, into the picture and one copy won’t cut it.
Master Slave: consistency is not too difficult because each piece of data has exactly one owning master. But then what do you do if you can’t see that master, some kind of postponed work is needed.
Master-Master: well if you can make it work then it seems to offer everything, no single point of failure, everyone can work all the time. Trouble is it very hard to preserve absolute consistency. See the wikipedia article for more.
https://stackoverflow.com/questions/3736969/master-master-vs-master-slave-database-architecture
In master-slave, the master is the one which generally does the write and reads can be distributed across master and slave; the slave is like a hot standby. The main problem happens when there is an automatic switchover facility for HA when a master dies.
I will add a word here about database clusters. I used to work shortly in a project with a big Oracle RAC system, and have seen the problems related to maintaining it in the context of the data that scaled out with time. We needed Oracle support and also an expert in storage/SAN networking to balance disk usage. I am however no expert. With this disclaimer -Oracle RAC is said to be masterless, I will consider it to be a pseudo-master-slave architecture as there is a shared ‘master’ disk that is the basis of its architecture. This will mean that the slave (multi oracle instances in different nodes) can scale read, but when it comes to writing things are not that easy. Here is a quote from a better expert
I’ll start this blog post with a quick disclaimer. I’m what you would call a “born and raised” Oracle DBA. My first job, 15 years ago, had me responsible for administration and developing code on production Oracle 8 databases. Since then, I’ve had the opportunity to work as a database architect and administrator with all Oracle versions up to and including Oracle 12.2. Throughout my career, I’ve delivered a lot of successful projects using Oracle as the relational database componen….
Although you can scale read performance easily by adding more cluster nodes, scaling write performance is a more complex subject. Technically, Oracle RAC can scale writes and reads together when adding new nodes to the cluster, but attempts from multiple sessions to modify rows that reside in the same physical Oracle block (the lowest level of logical I/O performed by the database) can cause write overhead for the requested block and affect write performance. This is well known phenomena and why RAC-Aware applications are a real thing in the real world. …
With the limitations for pure write scale-out, many Oracle RAC customers choose to split their RAC clusters into multiple “services,” which are logical groupings of nodes in the same RAC cluster.
Splitting writes from different individual “modules” in the application (that is, groups of independent tables) to different nodes in the cluster. This is also known as “application partitioning” (not to be confused with database table partitions).
In extremely un-optimized workloads with high concurrency, directing all writes to a single RAC node and load-balancing only the reads.
https://aws.amazon.com/blogs/database/amazon-aurora-as-an-alternative-to-oracle-rac/
Note that for scalability there can be clusters of master-slave nodes handling different tables, but that will be discussed later).
Obviously, this is done by a third node which is neither master or slave as it can only know if the master is gone down or not (NW down is also master down). This is essentially flawed.
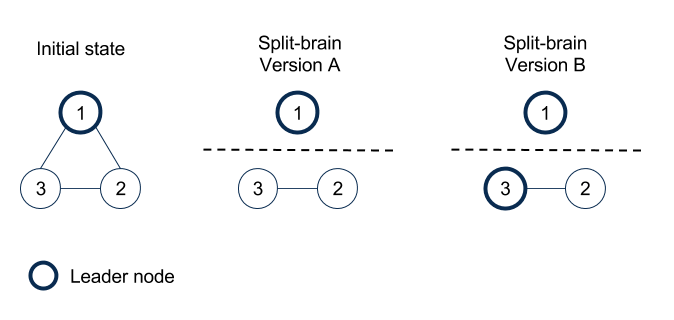
The Split Brain Curse -High Availability in a Master-Slave auto failover System
In a master slave-based HA system where master and slaves run in different compute nodes (because there is a limit of vertical scalability), the Split Brain syndrome is a curse which does not have a good solution.
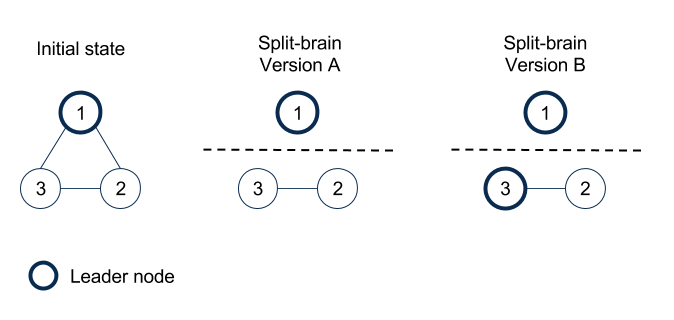
The Split brain syndrome — if there is a network partition in a cluster of nodes, then which of the two nodes is the master, which is the slave? Depends on where the NW partition happens; It seems easy to solve, but unless there is some guarantee that the third node/common node has 100% connection reliability with other nodes, it is hard to resolve. We were using pgpool-2 and this was I guess one of the bugs that bit us. If you are the type who think that rare things do not happen, in the computer world, you will never walk in the street at any time a meteor could hit your head.
Here is a short snippet with something that I was a part of trying to solve- analyzed by a colleague wrestling to make the pgpool work a few years back, basically automatic failover of a master-slave system.
· WE have two pgpool and two postgresql services configured as master and standby in to VMs. In case of postgresql, they are configured as active-standby. A virtual IP resides on the master pgpool and migrates to standby pgpool in case of failure.
· In normal working, all DB calls pass through the master pgpool which redirects them to the master postgresql node.
· The standby postgresql keeps replicating data from the master node using WAL log synchronization.
· If the master postgresql node goes down/crashes, any of the two pgpool triggers a failover and promotes the standby postgresql as new master. When the old master node comes back up, it is brought as a standby node.
Problem:
With the current implementation, we have the following issues/short-comings:
· If the pgpool node that detects a master postgresql failure is on the same node, as the failed master, then it has to trigger a remote failover to the other postgresql node using SSH. If there is an SSH failure at that moment, the failover will fail, resulting in a standby-standby situation.
· If postgresql node gets detached from pgpool due to heavy load (this happens if pgpool is not able to make connections to postgresql), then there is no way to re-attach the node again. It has to be manually attached using repmgr library.
· In the above case, if the slave node detaches itself and master node goes down, then pgpool has no more nodes to trigger failover to. This again causes in a standby-standby scenario…
It is not just a Postgres problem, a general google search (below) on this should throw up many problems most such software, Postgres, MySQL, Elastic Search etc.
https://www.google.co.in/search?rlz=high+availabillity+master+slave+and+the+split+brain+syndrome
Before we leave this for those curious you can see here the mechanism from Oracle RAC to tackle the split-brain (all master-slave architectures this will crop up but never in a true masterless system)-where they assume the common shared disk is always available from all cluster; I don’t know in depth the RAC structure, but looks like a classical distributed computing fallacy or a single point of failure if not configured redundantly; which on further reading, they are recommending to cover this part.
Voting disk needs to be mirrored, should it become unavailable, cluster will come down. Hence, you should maintain multiple copies of the voting disks on separate disk LUNs so that you eliminate a Single Point of Failure (SPOF) in your Oracle 11g RAC configuration. http://oracleinaction.com/voting-disk/
Another from a blog referred from Google Cloud Spanner page which captures sort of the essence o fthis problem.
We use MySQL to power our website, which allows us to serve millions of students every month, but is difficult to scale up — we need our database to handle more writes than a single machine can process. There are many solutions to this problem, but these can be complex to run or require extensive refactoring of your application’s SQL queries
https://quizlet.com/blog/quizlet-cloud-spanner
These type of scenarios are common and a lot of instances can be found of SW trying to fix this. You may want to steer clear of this; the Database’s using the master-slave (with or without automatic failover) -MySQL, Postgres, MongoDB, Oracle RAC(note MySQL recent Cluster seems to use master less concept (similar/based on Paxos) but with limitations, read MySQL Galera Cluster)
You may want to choose a database that support’s Master-less High Availability( also read Replication )
- Apache Cassandra
Cassandra has a peer-to-peer (or “masterless”) distributed “ring” architecture that is elegant, easy to set up, and maintain.In Cassandra, all nodes are the same; there is no concept of a master node, with all nodes communicating with each other via a gossip protocol. https://www.datastax.com/wp-content/uploads/2012/09/WP-DataStax-MultiDC.pdf
Apache Cassandra does not use Paxos yet has tunable consistency (sacrificing availability) without complexity/read slowness of Paxos consensus. ( It uses Paxos only for LWT. (Here is a gentle introduction which seems easier to follow than others (I do not know how it works))
2. Google Cloud Spanner?
Spanner claims to be consistent and available Despite being a global distributed system, Spanner claims to be consistent and highly available, which implies there are no partitions and thus many are skeptical.1 Does this mean that Spanner is a CA system as defined by CAP? The short answer is “no” technically, but “yes” in effect and its users can and do assume CA. The purist answer is “no” because partitions can happen and in fact have happened at Google, and during (some) partitions, Spanner chooses C and forfeits A. It is technically a CP system. We explore the impact of partitions below.
First, Google runs its own private global network. Spanner is not running over the public Internet — in fact, every Spanner packet flows only over Google-controlled routers and links (excluding any edge links to remote clients).
One subtle thing about Spanner is that it gets serializability from locks, but it gets external consistency (similar to linearizability) from TrueTime
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/45855.pdf
3. Cockroach DB is an open source in-premise database of Cloud Spanner -that is Highly Available and strongly Consistent that uses Paxos type algorithm.
Writes are serviced using the Raft consensus algorithm, a popular alternative to Paxos. — https://www.cockroachlabs.com/docs/stable/strong-consistency.html
The main difference is that since CockroachDB does not have Google infrastructure to implement TrueTime API to synchronize the clocks across the distributed system, the consistency guarantee it provides is known as Serializability and not Linearizability (which Spanner provides). http://wp.sigmod.org/?p=2153
Cockroach DB maybe something to see as it gets more stable;
Scalability — Application Sharding and Auto-Sharding
This directly takes us to the evolution of NoSQL databases. Database scaling is done via sharding, the key thing is if sharding is automatic or manual. By manual, I mean that application developer do the custom code to distribute the data in code — application level sharding. Automatic sharding is done by NoSQL database like Cassandra whereas almost all older SQL type databases (MySQL, Oracle, Postgres) one need to do sharding manually.
Auto-sharding is a key feature that ensures scalability without complexity increasing in the code.
Here is a snippet from the net. It covers two parts, the disk I/O part (which I guess early designers never thought will become a bottleneck later on with more data-Cassandra designers knew fully well this problem and designed to minimize disk seeks), and the other which is more important touches on application level sharding.
Why doesn’t PostgreSQL naturally scale well?
It comes down to the performance gap between RAM and disk.
But if the data is sufficiently large that we can’t fit all (similarly fixed-size) pages of our index in memory, then updating a random part of the tree can involve significant disk I/O as we read pages from disk into memory, modify in memory, and then write back out to disk (when evicted to make room for other pages). And a relational database like PostgreSQL keeps an index (or other data structure, such as a B-tree) for each table index, in order for values in that index to be found efficiently. So, the problem compounds as you index more columns.
In general, if you are writing a lot of data to a PostgreSQL table, at some point you’ll need partitioning. https://blog.timescale.com/scaling-partitioning-data-postgresql-10-explained-cd48a712a9a1
There is another part to this, and it relates to the master-slave architecture which means master is the one that writes and slaves just act as a standby to replicate and distribute reads. (More accurately, Oracle RAC or MongoDB Replication Sets are not exactly limited by only one master to write and multiple slaves to read from; but either use a shared storage and multiple masters -slave sets to write and read to, in case of Oracle RAC; and similar in case of MongoDB uses multiple replication sets with each replication set being a master-slave combination, but not using shared storage like Oracle RAC. Please see above where I mentioned the practical limits of a psuedo master-slave system like shared disk systems)
Let us now see how this automatic sharding is done by Cassandra and what it means to data Modelling.
Part 2 : Cassandra Internals for Data Modelling
Cassandra Write — Intuition
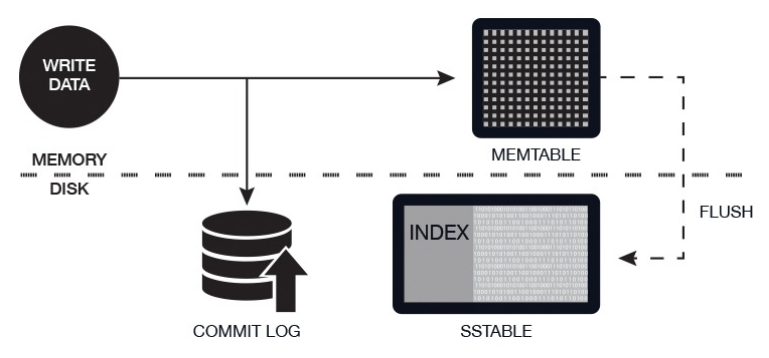
Note the Memory and Disk Part. The flush from Memtable to SStable is one operation and the SSTable file once written is immutable (not more updates). Many people may have seen the above diagram and still missed few parts. SSTable flush happens periodically when memory is full. Commit log has the data of the commit also and is used for persistence and recovering in scenarios like power-off before flushing to SSTable. It is always written in append mode and read only on startup. Since SSTable is a different file and Commit log is a different file and since there is only one arm in a magnetic disk, this is the reason why the main guideline is to configure Commit log in a different disk (not even partition and SStable (data directory)in a separate disk.
Cassandra performs very well on both spinning hard drives and solid state disks. In both cases, Cassandra’s sorted immutable SSTables allow for linear reads, few seeks, and few overwrites, maximizing throughput for HDDs and lifespan of SSDs by avoiding write amplification.
However, when using spinning disks, it’s important that the commitlog (commitlog_directory) be on one physical disk (not simply a partition, but a physical disk), and the data files (data_file_directories) be set to a separate physical disk. By separating the commitlog from the data directory, writes can benefit from sequential appends to the commitlog without having to seek around the platter as reads request data from various SSTables on disk. -http://cassandra.apache.org/doc/4.0/operating/hardware.html
Please, note that the SSTable file is immutable. This means that after multiple flushes there would be many SSTable. This would mean that read query may have to read multiple SSTables. Also, updates to rows are new insert’s in another SSTable with a higher timestamp and this also has to be reconciled with different SSTables for reading. To optimize there is something called periodic compaction that is done where multiple SSTables are combined to a new SSTable file and the older is discarded.
Note that Delete’s are like updates but with a marker called Tombstone and are deleted during compaction. However, due to the complexity of the distributed database, there is additional safety (read complexity) added like gc_grace seconds to prevent Zombie rows. This is one of the reasons that Cassandra does not like frequent Delete.
If you want to get an intuition behind compaction and how relates to very fast writes (LSM storage engine) and you can read this more
These SSTables might contain outdated data — e.g., different SSTables might contain both an old value and new value of the same cell, or an old value for a cell later deleted. That is fine, as Cassandra uses timestamps on each value or deletion to figure out which is the most recent value. However, it is a waste of disk space. It also slows down reads: different SSTables can hold different columns of the same row, so a query might need to read from multiple SSTables to compose its result.
For these reasons, compaction is needed. Compaction is the process of reading several SSTables and outputting one SSTable containing the merged, most recent, information.
This technique, of keeping sorted files and merging them, is a well-known one and often called Log-Structured Merge (LSM) tree.
https://github.com/scylladb/scylla/wiki/SSTable-compaction-and-compaction-strategies+others
This blog gives the internals of LSM if you are interested.
We have skipped some parts here. One main part is Replication. When we need to distribute the data across multi-nodes for data availability (read data safety), the writes have to be replicated to that many numbers of nodes as Replication Factor.
Also when there are multiple nodes, which node should a client connect to?
It connects to any node that it has the IP to and it becomes the coordinator node for the client.
The coordinator node is typically chosen by an algorithm which takes “network distance” into account. Any node can act as the coordinator, and at first, requests will be sent to the nodes which your driver knows about….The coordinator only stores data locally (on a write) if it ends up being one of the nodes responsible for the data’s token range --https://stackoverflow.com/questions/32867869/how-cassandra-chooses-the-coordinator-node-and-the-replication-nodes
Role of PARTITION Key in Write
Now let us see how the auto-sharding taking place. Suppose there are three nodes in a Cassandra cluster. Each node will own a particular token range.
Assume a particular row is inserted. Cassandra uses the PARTITION COLUMN Key value and feeds it a hash function which tells which of the bucket the row has to be written to.
It uses the same function on the WHERE Column key value of the READ Query which also gives exactly the same node where it has written the row.
A Primary key should be unique. More specifically a ParitionKey should be unique and all values of those are needed in the WHERE clause. (Cassandra does not do a Read before a write, so there is no constraint check like the Primary key of relation databases, it just updates another row)
The partition key has a special use in Apache Cassandra beyond showing the uniqueness of the record in the database -https://www.datastax.com/dev/blog/the-most-important-thing-to-know-in-cassandra-data-modeling-the-primary-key
The relation between PRIMARY Key and PARTITION KEY.
PARTITION KEY == First Key in PRIMARY KEY, rest are clustering keys
Example 1: PARTITION KEY == PRIMARY KEY== videoid
CREATE TABLE videos (
…PRIMARY KEY (videoid)
);
Example 2: PARTITION KEY == userid, rest of PRIMARY keys are Clustering keys for ordering/sortig the columns
CREATE TABLE user_videos (
PRIMARY KEY (userid, added_date, videoid)
);
Example 3: COMPOSITE PARTITION KEY ==(race_year, race_name)
CREATE TABLE rank_by_year_and_name (
PRIMARY KEY ((race_year, race_name), rank)
);
Now here is the main intuition. Part 1
For writes to be distributed and scaled the partition key should be chosen so that it distributes writes in a balanced way across all nodes.
But don’t you think it is common sense that if a query read has to touch all the nodes in the NW it will be slow. Yes, you are right; and that is what I wanted to highlight. Before that let us go shallowly into — Cassandra Read Path
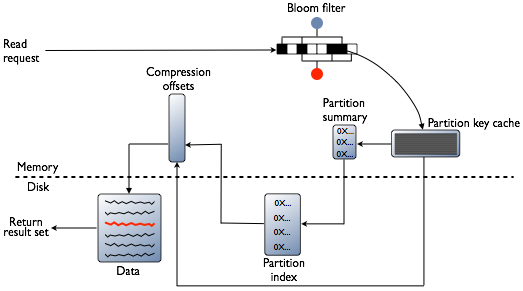
Now here is the main intuition. Part 2
For reads to be NOT distributed across multiple nodes (that is fetched and combine from multiple nodes) a read triggered from a client query should fall in one partition (forget replication for simplicity)
This is illustrated beautifully in the diagram below
You can see how the COMPOSITE PARTITION KEY is modeled so that writes are distributed across nodes and reads for particular state lands in one partition.
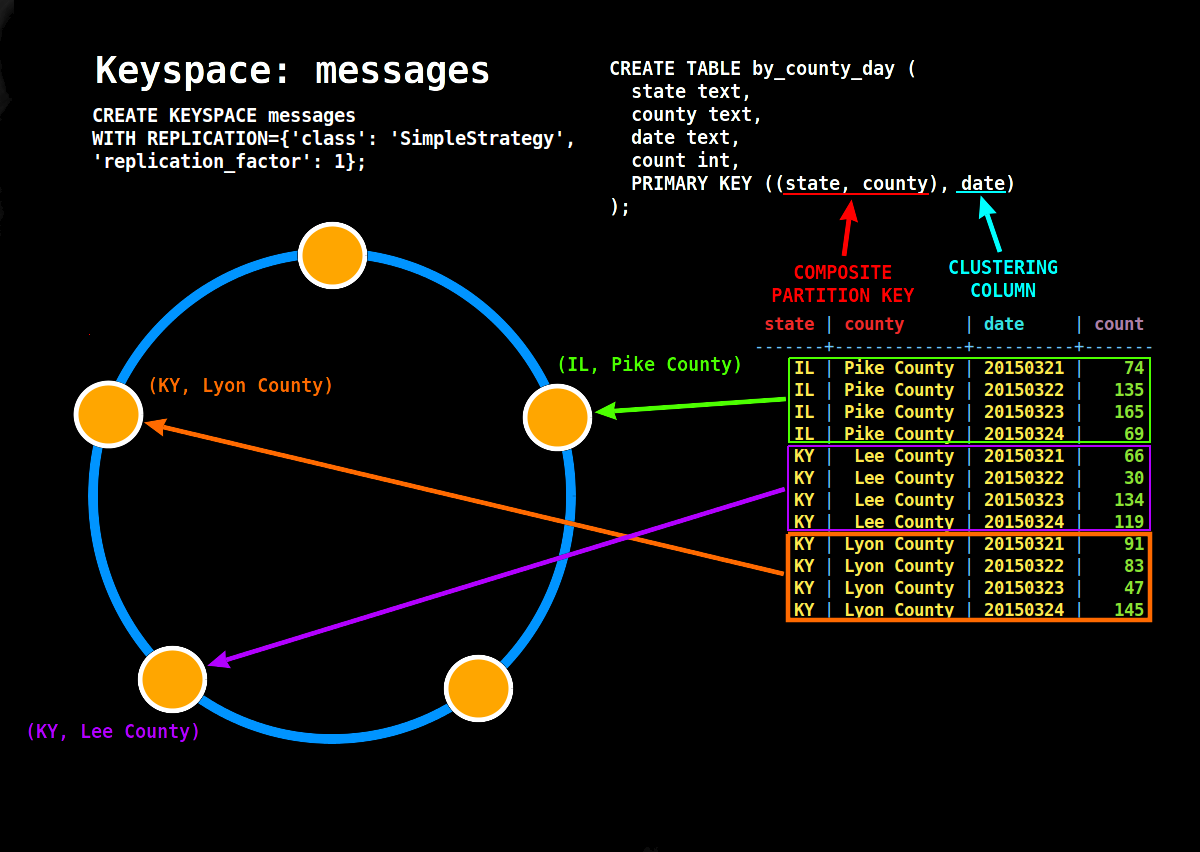
To have a good read performance/fast query we need data for a query in one partition read one node.There is a balance between write distribution and read consolidation that you need to achieve, and you need to know your data and query to know that.
The point is, these two goals often conflict, so you’ll need to try to balance them.
Conflicting Rules?
If it’s good to minimize the number of partitions that you read from, why not put everything in a single big partition? You would end up violating Rule #1, which is to spread data evenly around the cluster.
The point is, these two goals often conflict, so you’ll need to try to balance them.
Model Around Your Queries
The way to minimize partition reads is to model your data to fit your queries. Don’t model around relations. Don’t model around objects. Model around your queries. Here’s how you do that -
https://www.datastax.com/dev/blog/basic-rules-of-cassandra-data-modeling
This is the most essential skill that one needs when doing modeling for Cassandra.
https://www.datastax.com/dev/blog/the-most-important-thing-to-know-in-cassandra-data-modeling-the-primary-key
A more detailed example of modeling the Partition key along with some explanation of how CAP theorem applies to Cassandra with tunable consistency is described in part 2 of this serieshttps://hackernoon.com/using-apache-cassandra-a-few-things-before-you-start-ac599926e4b8





