
This series of posts present an introduction to Apache Cassandra. It discusses key Cassandra features, its core concepts, how it works under the hood, how it is different from other data stores, data modelling best practices with examples, and some tips & tricks.
Data flow in Cassandra looks like this:
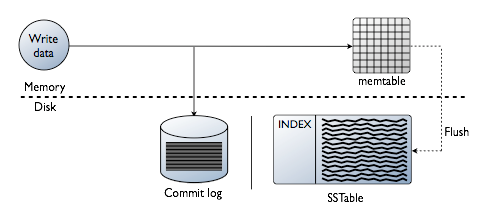
Incoming data is written into a commit log as well as in an in-memory store. Once the in-memory store is full, data is flushed onto disk in SSTables. Purpose of committing data into commit log is to provide fault tolerance. If a node goes down while there was still data in in-memory table which was yet to be persisted, on restart, node restores it’s in-memory state using commit log and resumes operation normally.
Core Cassandra Concepts
Two concepts are of utmost importance to understand Cassandra and its data modelling.
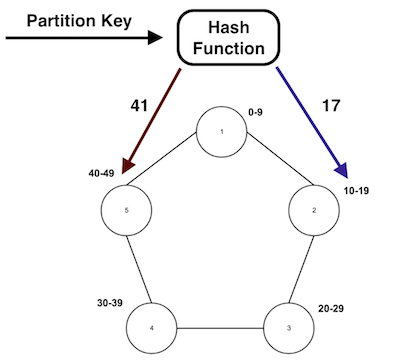
Partition Key: determines on which node in a Cassandra cluster data is going to be stored.
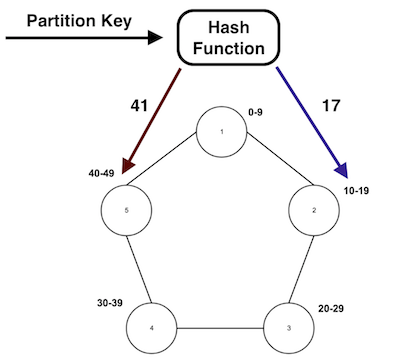
The hash function or Cassandra partitioner decides, based on the partition key, which data to send at what node.
For example, say you want to store data of four cities A, B, C and D. You have a 2 node Cassandra cluster. You choose city name as partition key. To store this data Cassandra will create four partitions (against 4 unique cities), 2 on each node.
Clustering Key: determines how data is sorted within a partition. Continuing on our last example, let’s say each incoming data point has a city name (A, B, C or D) and an associated timestamp. You can tell Cassandra to use timestamp as clustering key to store data in sorted order within a partition. This will enable efficient data lookup within a partition.
In short, partition key helps Cassandra in locating the node with specific data, while clustering key helps in efficiently finding data within a partition.
Both partition and clustering key can be composite.
Column Family Store
As discussed earlier, Cassandra is neither a row based store nor it is a column based store, rather it is a column family store. But what does that mean?
One way to understand how Cassandra stores its data is this data structure:
Map<RowKey, SortedMap<ColumnKey, ColumnValue>>
Each row is mapped to a node using partition key, and the value is a set of key value pairs sorted by clustering key.

In other words, Cassandra is a partitioned row store, where data is partitioned by partition key and, within a partition, sorted by clustering key.
Next: Apache Cassandra, Part 5: Data Modelling with Examples







