
Row vs Column Stores
When talking about data stores it is helpful to keep this image in mind.
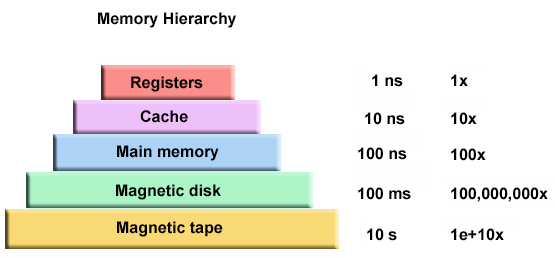
A disk read is an expensive operation and should be used in minimum to ensure performance of a data system. With this image in mind, let’s take data shown below as an example to look at various types of storage engines and see for what scenario each engine is optimized for.
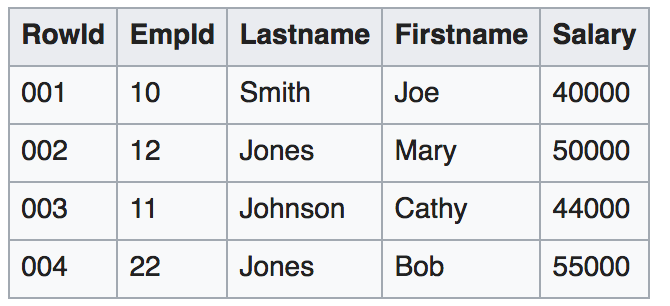
Here we have data of employees, their ids, first and last names, and salaries.
Row Oriented Stores
A row oriented store persists this data under the hood like this:

Interesting thing to note here is the column values that belongs to a single row are stored together. This makes it easy and cheap in terms of IO cost to read a single row. You go to desired row in a single disk seek, thanks to primary index, and find all the data in that row. Row oriented stores are efficient in scenarios where you need to access fewer rows and intend to use most of the data available in rows. This data access pattern is very common in OLTP systems, for example a university management, a banking portal, etc. But imagine if you need to find out median salary. For that you will have to scan the complete table and that will involve a lot of disk reads.
Column Oriented Stores
A column oriented store would save the same information like this

Here, unlike a row store, all column values from a particular column are stored together. Now, if we want to calculate median salary, it will be very fast because it involves only one disk seek. But, if we want to get complete information of a particular employee, we will end up doing a lot of IO operations.
In a column oriented store, number of values in each row should be same. This allows joining rows using index, which would be impossible to do if number of values are unequal. Column oriented stores are useful in OLAP scenarios where generally specific columns are of interest and queries are centered around these columns.
Cassandra is neither a row oriented store nor it is a column oriented store, rather is is column family store. To understand how it is different from a row store, lets consider a scenario where we want to store temperature values. In a row based store we typically create a table temperatures with two columns (1) timestamp (2) value. On data insertion temperatures table will grow vertically. But in Cassandra, it can be a very valid design to store data like this:

Here every new entry is creating a new column. (Cassandra supports up to 2 Billion columns).
Now consider another example where we need to store various attributes of fruits. Following is a perfectly valid data model in Cassandra

But you cannot do this in a column oriented store because, recall, you have to have same number of columns for each row.
Hence, Cassandra is neither a row oriented store, nor it is a column oriented store because it does things differently than both of those. But the question remains: if Cassandra is a column family store then what exactly does it mean and how is it different ? Hang on, I cover this in future posts but first you need to understand a few core concepts of Cassandra.







