

Welcome to Lesson Seven ‘Cassandra Advanced Architecture and Cluster Management’ of the Apache Cassandra Certification Course. This lesson will cover the advanced architecture of Cassandra and cluster management in Cassandra.
Let us begin with the objectives of this lesson.
Objectives
After completing this lesson on Cassandra Advanced Architecture and Cluster Management, you will be able to:
-
Explain partitioning
-
Describe replication strategies and consistency levels in Cassandra
-
Explain time to live and tombstones
-
Demonstrate the use of the nodetool utility
-
Demonstrate the installation and configuration of the OpsCenter utility.
In the next section, let us understand Partitioning.
Partitioning
Cassandra uses partitioners to distribute data evenly across cluster nodes. A partition key is used for data partitioning. It can be a single column or multiple columns.
Three types of partitioners are available in Cassandra:
-
Murmur3Partitioner
-
RandomPartitioner
-
ByteOrderedPartitioner
The partitioner is specified in the cassandra.yaml file.
In the next section, let us understand Murmur3Partitioner.
Murmur3Partitioner
The Murmur3Partitioner is currently the default partitioner in Cassandra.
Some of the features of this partitioner are:
-
It uses the MurmurHash function.
-
The MurmurHash function is a non-cryptographic hash function that creates a 64-bit hash value of the partition key.
-
The function token() can be used in CQL to select a range of rows based on the hash value of the partition key.
Let us focus on RandomPartitioner in the next section.
RandomPartitioner
The RandomPartitioner was the default partitioner in earlier versions of Cassandra. It is similar to the Murmur3Partitioner except that it uses the MD5 or message-digest version 5 hash function to calculate the hash value.
MD5 is a widely-used cryptographic hash function that produces a 128-bit hash value based on the key. It is considered cryptographic because it performs a one-way encryption.
Let us focus on ByteOrderedPartitioner in the next section.
ByteOrderedPartitioner
Some of the features of The ByteOrderedPartitioner are:
-
It orders rows using partition key values.
-
It performs distribution using the hexadecimal values of the partition key.
-
This enables ordered scans with the use of the primary key.
-
The downside is that this type of ordering makes load balancing difficult.
Let us focus on Replication of Data in the next section.
Replication of Data
Data replication is used for fault tolerance. A replication factor of three implies a fault tolerance of two. This means that even if two machines fail simultaneously, the third machine will provide the data.
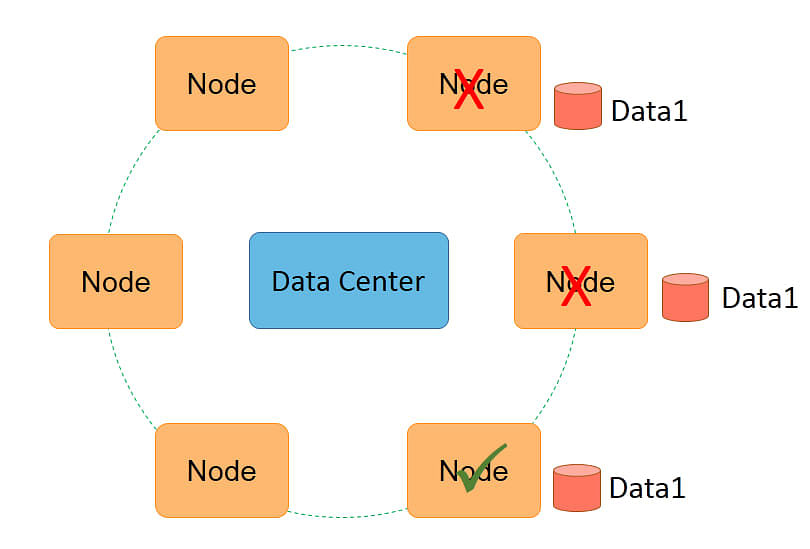
When a machine that has a data replica fails, Cassandra will automatically try to create a replica on another machine so that the replication count is brought back to three. There is a chance of data loss only if all three machines fail simultaneously.
The probability of that happening is very low. Suppose the mean time to failure or MTTF of each machine is one in 365. This means that each machine is likely to fail once in 365 days. In this case, the probability of three machines failing simultaneously is 1 / (365*365*365), which is one in 200 million.
This is a very low probability. Therefore, the presence of three replicas provides good fault tolerance even with commodity-type hardware.
Let us focus on Replication Strategy in the next section.
Replication Strategy
The replication strategy determines how multiple replicas of a data row are maintained. Replication is specified at the keyspace level, and different keyspaces can have different strategies.
The replication strategy is specified during the creation of a keyspace. The strategy for a keyspace cannot be modified, but the number of replicas can be modified.
Cassandra provides two common replication strategies:
-
SimpleStrategy and
-
NetworkTopologyStrategy.
In the next section, let us focus on SimpleStrategy.
SimpleStrategy
SimpleStrategy is the replication strategy for single-rack clusters. It is used within a data center and is suitable for test or development clusters.
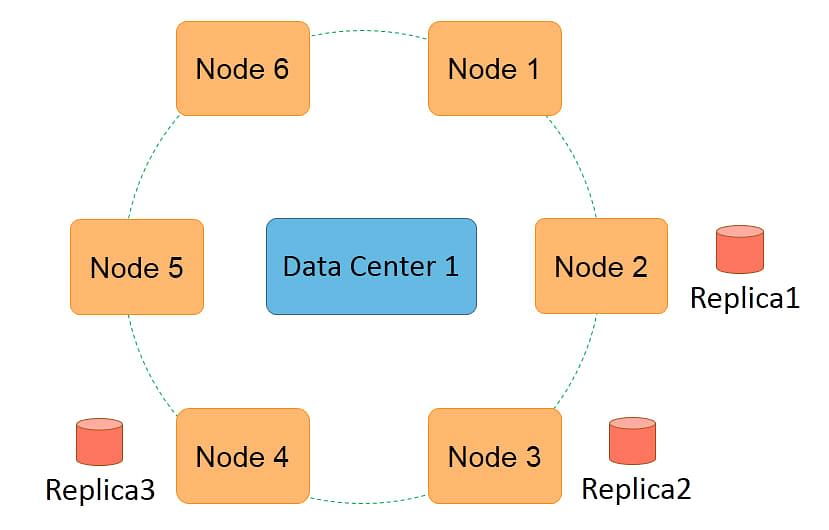
In this replication strategy, the first copy is stored according to the partitioner.
The second copy is placed on the node adjacent to where the first copy was placed.
The third copy is placed on the node adjacent to the second node, and this proceeds in a clockwise direction.
The replication factor is specified as an option and informs how many replicas need to be maintained. The statements show the creation of a keyspace called testDB with SimpleStrategy for replication. They specify the replication factor as three. This means Cassandra will try to keep three copies of each data row in the keyspace testDB.
In the next section, let us focus on NetworkTopologyStrategy.
NetworkTopologyStrategy
NetworkTopologyStrategy is used for multi-rack data centers and is suitable for production clusters and multi-data center clusters.
In this strategy, the number of replicas in each data center can be specified while creating the keyspace. Replicas are placed on different racks within a data center.
Similar to SimpleStrategy, NetworkTopologyStrategy decides the first node based on the partitioner. Subsequent replicas are placed by checking for a different rack in the ring, in a clockwise direction.
The statements show the creation of a keyspace called testDB with NetworkTopologyStrategy.

It specifies three replicas in data center 1 and one replica in data center 2, thus providing a total of four replicas.
Therefore, even if data center 1 fails, you can access the data from data center 2.
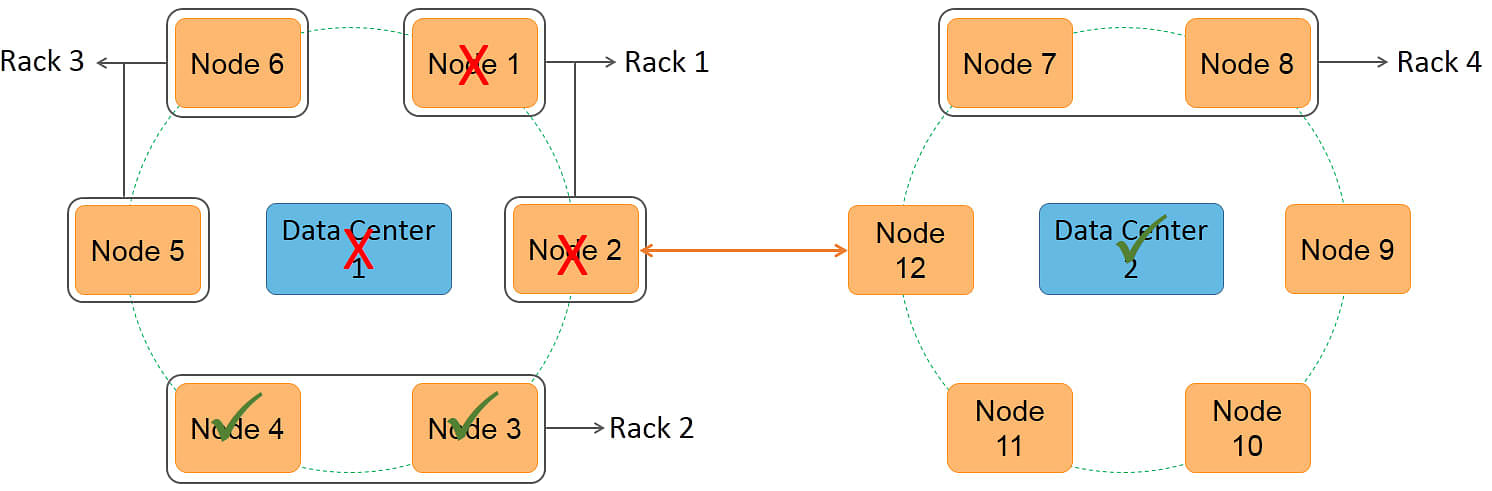
The presence of multiple replicas in NetworkTopologyStrategy ensures two things.
First, it ensures fault tolerance because even if one rack fails, a copy of the data is available on another rack within the data center. Similarly, even if one data center fails, you can access the data from another data center.
Second, it facilitates data locality. Accessing data in the same node is faster. Therefore, even if one node is busy, you can find another node where the data is local.
Let us look into the Replication Example in the next section.
Replication Example
Let us discuss an example of replication with NetworkTopologyStrategy.
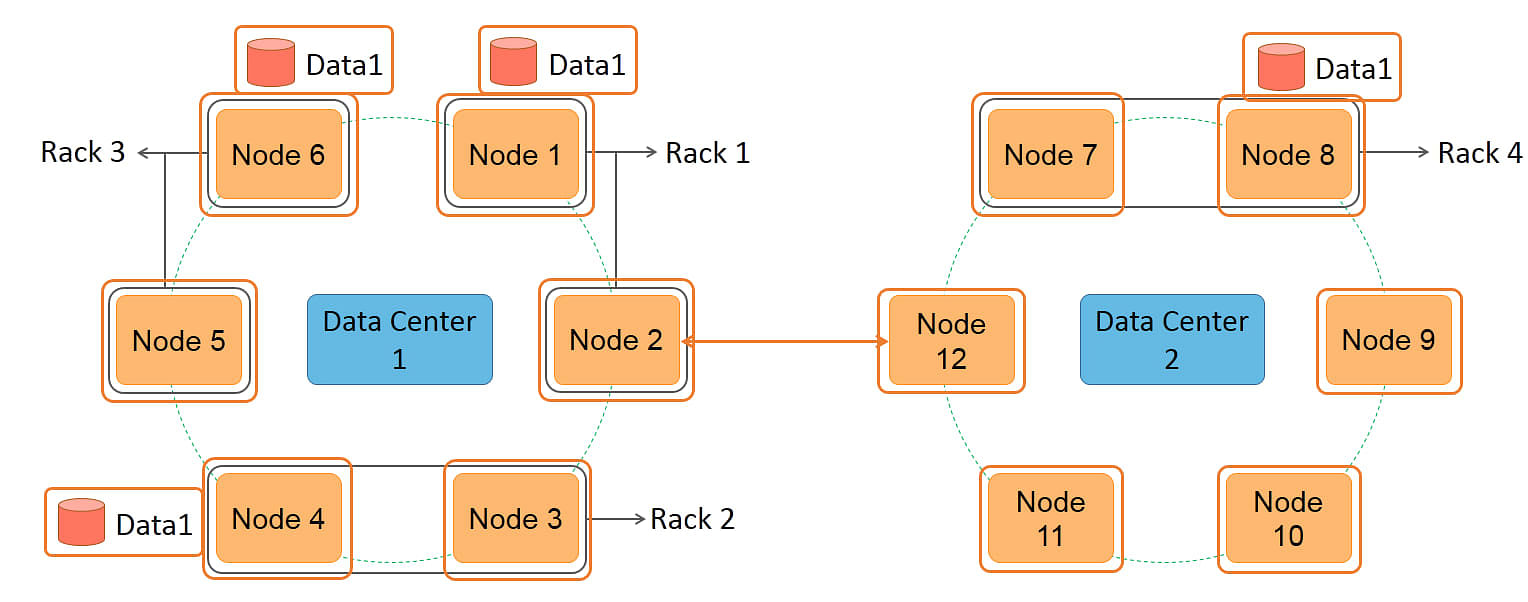
There are three data copies in data center 1 and one copy in data center 2. Nodes 1 to 6 are present in data center 1 and nodes 7 to 12 are present in data center 2.
The first copy is placed on node 1 as determined by the partitioner.
The second copy is placed on node 4 as it is present on a different rack while moving clockwise in the ring from node 1.
The third copy is placed on node 6 as it is present on a different rack, rack 3. Node 6 is present after node 4 while moving clockwise on the ring. This completes the allocation of three copies for data center 1.
The fourth copy is placed on node 8 in data center 2 as determined by the partitioner.
In the next section, let us learn about Tunable Consistency.
Tunable Consistency
Let us discuss tunable consistency now. Cassandra provides tunable consistency for better performance, that is, it provides a tradeoff between consistency and performance. A higher consistency implies a slower response to reads and writes.
In Cassandra, consistency can be specified for each read and write operation. One is the default consistency and is specified in the configuration file.
In the earlier versions of Cassandra, consistency was specified as part of CQL, but in the latest version, consistency is specified as part of the command line interface, cqlsh.
A quorum of replicas is considered for some consistency levels.
A quorum of replicas signifies a quantity greater than 50% of the replicas. This constitutes a majority of replicas. For a replication count of five, a quorum refers to having at least three replicas.
A local quorum requires a presence of more than 50% of the replicas within a data center. In our earlier example with three replicas in data center 1, a local quorum requires at least two replicas.
In the next section, let us learn about Read Consistency.
Read Consistency
The following are the descriptions of the different levels of consistency that can be specified for a read operation:
-
ONE - Returns as soon as one replica of the data is received. This is the lowest consistency level for a read.
-
QUORUM - Returns as soon as a quorum of replicas is received.
-
LOCAL_QUORUM - Returns the moment a quorum of replicas within the data center is received.
-
EACH_QUORUM - Returns after a quorum of replicas is received from each data center where replicas are specified.
-
ALL - Returns only after all the replicas are received.
When multiple replicas are received, the replica with the most recent timestamp is returned as the result of the read.
In the statements given below, a consistency level of LOCAL_QUORUM is set in cqlsh, and a read is executed using the SELECT statement.
CONSISTENCY LOCAL_QUORUM;
Select * from stocks where ticker = ‘ABC’;
The SELECT statement will fail on the VM because the replication count has been set to three, in which case, a quorum is two replicas. However, data is present on only one node.
In the next section, let us learn about Write Consistency.
Write Consistency
The following are the descriptions of the different levels of consistency that can be specified for a write operation:
-
ANY - Returns as soon as a replica is written to any node or a commitlog is written.
-
ONE - Returns as soon as a replica is written to the correct node.
-
QUORUM - Returns the moment a quorum of replicas is written.
-
LOCAL_QUORUM - Returns after a quorum of replicas is written within the data center.
-
EACH_QUORUM - Returns after a quorum of replicas is written in each data center where replicas are maintained.
-
ALL - Returns only after all the replicas are written.
The consistency level of ANY provides the fastest response but has the least consistency. The consistency level of ALL provides the most consistent write but has a slower performance.
The write consistency applies to insert, update, and delete operations.
In the given statements, a consistency level of ANY is specified in cqlsh, and a write is executed with an UPDATE command. This will return immediately after writing to the commitlog.
CONSISTENCY ANY;
update stocks set value = 45 where ticker = ‘ABC’ and year = 2011;
In the next section, let us learn about Read or Write failure.
Read or Write Failure
Read and write operations will fail if a certain consistency level cannot be achieved due to node failure.
Node failure will occur in one of the following cases:
-
If LOCAL_QUORUM is specified and the number of live nodes is less than the local quorum.
-
If ALL is specified and one of the replica nodes is down.
-
If EACH_QUORUM is specified and the number of live nodes on any data center is less than the quorum.
In a single node cluster with a replication factor of three, any consistency level other than ONE or ANY will fail as shown.
In the given set of statements, a consistency level of LOCAL_QUORUM is set in cqlsh, and an UPDATE statement is executed.

In the VM, this fails with the message as shown since the local quorum is two replicas.
In the next section, let us learn about Hinted Handoff.

Hinted Handoff
Hinted handoff is used during data writes in Cassandra when one of the nodes to write to is down.
The process is as follows:
-
One of the live nodes acts as the temporary write node.
-
Commitlog is written by the temporary node so that the write is persistent.
-
Write is completed as if written to the actual node.
-
The temporary node will send the data to the actual node once the node is up.
-
The consistency level of ANY for write succeeds even when writing to the temporary node.
In the next section, let us focus on Time to live.
Time to Live
In Cassandra, it is possible to store data only for a limited period. Time to live or TTL refers to the number of seconds for which data should be stored. It is specified during an insert or update in terms of the number of seconds.
Data is removed when the data expires and is made null. The row, however, is not deleted. In the given statements, the value column is updated in the Stocks table using the time to live for one day.
update stocks
USING TTL 86400
set value = 60
where ticker = ‘XYZ’ and year = 2014;
Note that 86400 seconds represents the number of seconds in 24 hours. This data will be removed immediately after 24 hours.
In the next section, let us learn about Tombstones.
Tombstones
In Cassandra, distributed deletes can cause anomalies when the consistency level is reduced. To overcome this, deletes are handled in the following manner:
-
Instead of removing the data during a delete operation, a special value called tombstone is created.
-
Tombstones are propagated to all replicas.
-
After all the replicas are removed, the tombstone still exists.
-
Tombstones are removed during compaction after a grace period.
In the given statements, a consistency level of one is set in cqlsh, and a DELETE statement is executed.
Consistency ONE;
delete from stocks
where ticker = ‘XYZ’ and year = 2013;
The statement returns the moment one replica is deleted, but a tombstone is created so that a subsequent read or write will know that this data has been deleted.
In the next section, let us learn about Monitoring the Cluster.
Monitoring the Cluster
Cassandra is highly fault tolerant, so an administrator needs less effort to monitor the cluster.
The following are a couple of utilities available to monitor the cluster:
-
The nodetool utility can be used to monitor and administer the cluster.
-
DataStax provides an OpsCenter utility that can be used to:
- monitor the cluster through a graphical interface from one’s browser.
- modify configuration parameters
- add nodes to the cluster.
- stop or start servers.
In the diagram, a nodetool utility is run on a VM, and the status of one node in the cluster is shown.

You can also see that the node is up and running normally. Further, you can see the node’s address and load on the node.
In the next section, let us learn about Nodetool Options.
Nodetool Options
The table shows various options for the nodetool utility along with their descriptions. You can view all the options using the command ‘nodetool help.’
|
Option |
Description |
|
dstats |
Shows Statistics On Column Families Or Tables |
|
compact |
Forces compaction of one or more column families |
|
decommission |
Decommission The Specified Node |
|
describecluster |
Show Cluster Information |
|
Describe ring |
Shows ring token range information |
|
join |
Adds this node to the ring |
|
status |
Shows cluster status information |
Install and Configure OpsCenter
With a few simple steps, you can install and configure OpsCenter from DataStax to monitor and administer the cluster.
To install OpsCenter on the VM, execute the given commands.

In the next section, let us focus on Monitoring with OpsCenter.
Monitoring with OpsCenter
You can use the browser to connect to the OpsCenter from Windows and monitor and administer the cluster. Access the OpsCenter with the given link, where the vm address is the one used in PuTTY to connect to the VM.
You can see cluster-, node-, and activity-level information and information on each node in the cluster. You can also use administration screens to add nodes to the cluster.
The following image shows the initial screen of the OpsCenter.
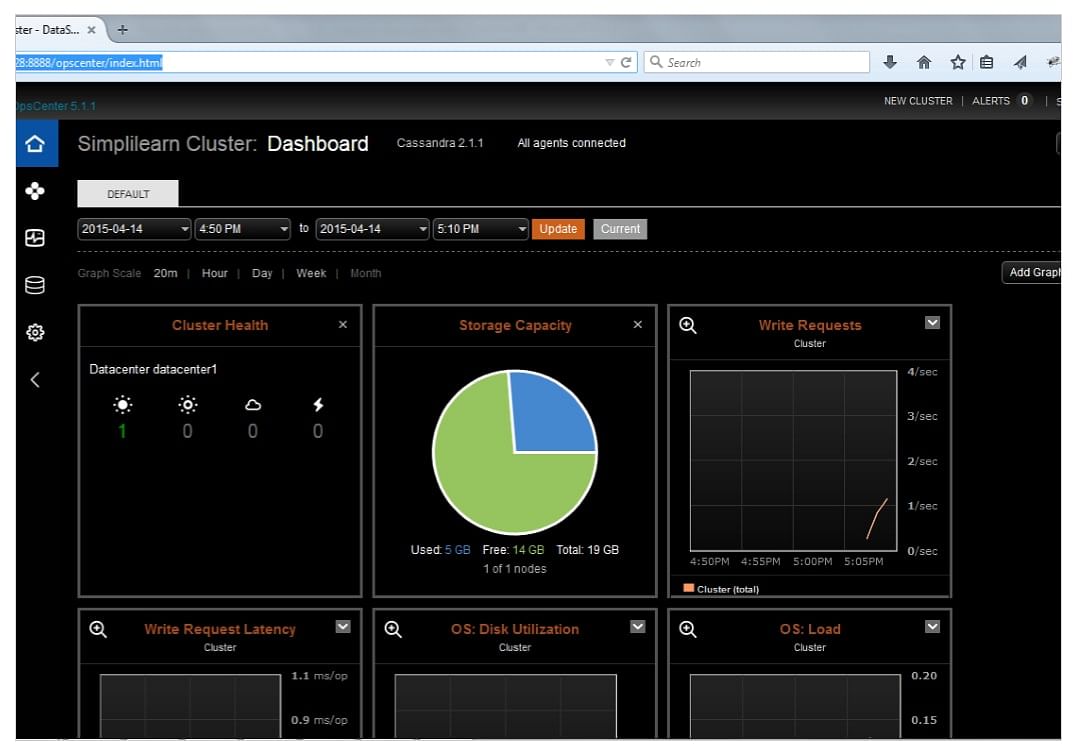
It displays a dashboard with various graphs that show the status of the cluster. There are graphs on Cluster Health, Storage Capacity, Write Requests, Write Request Latency, Disk Utilization at the operating system level, and the load on the OS.
The OpsCenter also displays the keyspace information.
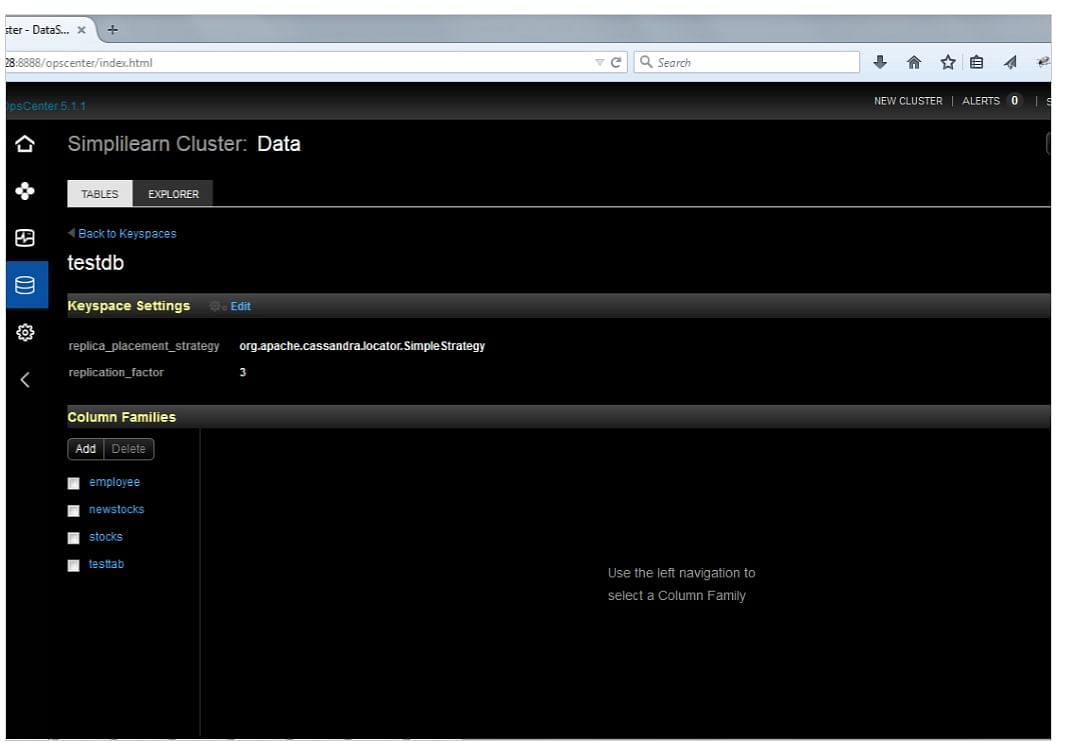
You can click on the database icon on the left to view the keyspace and user keyspace information. You can expand the keyspace to look at the tables in it. Tables are shown under the heading ‘Column Families.’
The diagram shows a screenshot of the OpsCenter screen where the database is selected, and the information about the keyspace testDB is displayed.
The diagram also shows the replication settings for keyspace testDB and also lists the tables under the heading ‘Column Families.’ Remember that Cassandra sometimes uses the term ‘column families’ for tables.
In the next section, let us learn about Administer using OpsCenter.
Administer using OpsCenter
The OpsCenter can be used to administer the cluster in various ways.
You can use cluster actions->Add Nodes to add a node.
On the Add Nodes screen, provide sudo user information to install the required software.
Additional configuration can also be done here. Finally, click on Add Nodes to start the installation.
The image below shows the Add Nodes screen where you can specify the address of the nodes to be added and the information, as mentioned earlier.
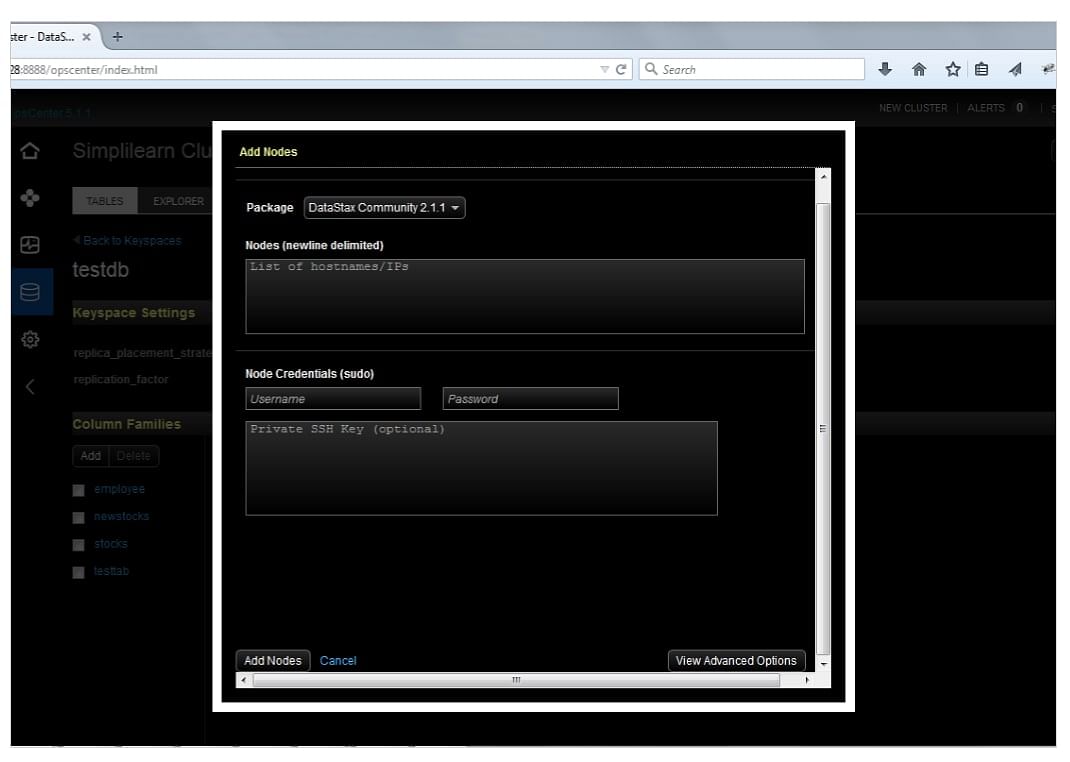
It also shows the Add Nodes and Cancel options at the bottom of the screen.
Summary
Let us summarize the topics covered in this lesson.
-
Cassandra uses the Murmur3Partitioner by default, but the RandomPartitioner and the ByteOrderedPartitioner are also available.
-
The first copy of data is placed on a node based on the partitioner, while subsequent copies are placed based on the replication strategy.
-
SimpleStrategy and NetworkTopologyStrategy are available for replication.
-
Consistency is tunable in Cassandra, and you can set the consistency for each read and write operation.
-
Various consistency levels provide a tradeoff between speed and consistency of data.
-
Hinted handoffs are used to make writes faster even if the responsible node is down.
-
Tombstones are used to handle distributed deletes.
-
Nodetool and OpsCenter can be used to monitor and administer a cluster.
Conclusion
This concludes the lesson ‘Cassandra Advanced Architecture and Cluster Management.’ In the next lesson, we will learn about the Hadoop Ecosystem around Cassandra.







